Team:UESTC-software/js/basic/threeLevel
/**
* Created by MacBook Air on 2016/9/19. * Modify by Junwa on 2016/10/7 */
var data = [
[
{
name:"Description",
img:" ",
mediaSrc:"https://2016.igem.org/Team:UESTC-software/Description",
catalogue:['Background','Biotechnology Availability','Project abstract','Reference'],
content: +
",
mediaSrc:"https://2016.igem.org/Team:UESTC-software/Description",
catalogue:['Background','Biotechnology Availability','Project abstract','Reference'],
content: +
'Contents
- 1 Background
- 2 Biotechnology Availability
- 3 Project abstract
- 4 Reference
- 5 The optimization of the front-end
- 6 The design of back-end
- 7 Framework of our website
- 8 Why do we choose DNA?
- 9 What do Bio101 develop or improve as a DNA information storage system?
- 10 Reference
- 11 Encoding
- 12 Decoding
- 13 Example
- 14 Dry-lab testing
- 15 Wet lab validation
- 16 Improve the core algorithms
- 17 Find a better encoding method
- 18 Enable random access and information rewriting
- 19 Decrease the cost of synthesize the sequences
- 20 Experiment further to verify the feasibility
- 21 Bio1024
- 22 Bio2048
- 23 Members
- 24 Mentors
- 25 Collaborations and sharing, the key to step forward
- 26 With More Humanities, Do More Practices.
Background
'+ 'Living in an era of information explosion, digital production, transmission and storage so far have not only revolutionized the way information is accessed and used, but have made archiving of information an increasingly complex task [1]. Have you been perplexed by vast quantities of information? And have you ever imagine that there exists a practical, high-capacity, low-maintenance, and even self-copy information storage medium which would be still useful after thousands of years? It wouldn’t be only a dreamy illusion anymore because of the appearance of great DNA storage technology.
' + '<img src=" " />
" />
Fig.1. Genome controls the growth and development of human being.
DNA, one of the most miraculous masterpiece created by Nature as the stable genetic material, hold a great promise for high-density, long-term and massive information storage. For example, human genome, just 3 billion base pairs, contains all of the complex biology information of human being, including metabolism, development, production and many other functions (Figure 1). Why do not we utilize DNA to store information? Researches indicate that it is extremely dense, and spectacular high-capacity with a raw limit of 1 exabyte/mm3(109 GB/mm3)[2]. In other word, every gram of DNA is equivalent to 14 thousand of 50GB blue-ray discs 233 x 3 TB hard disks with a weight of more than 151 kg. Meanwhile, compared with now routinely used information storage media, DNA can be stored up to thousands of years and still readable (Figure 2)[2]. Grass R N, et al developed an innovative preservation of digital information on DNA which presumably can last 1 million years in silica[3]. In conclusion, DNA with a great number of virtues in information storage makes it an ideal archival material.
'+ '<img src=" " />
" />
Fig.2. DNA storage as the bottom level of the storage hierarchy.[2]
Biotechnology Availability
'+ 'You may wonder how a piece of arbitrary information is stored into DNA molecules . It owes to the development of DNA sequencing (Figure 3) and synthesis technologies which make it possible to archive and read data in DNA. In 1977, Frederick Sanger adopted primer-extension strategy to develop the DNA sequencing method "DNA sequencing with chain-terminating inhibitors"[4], and it directly facilitated human genome project (HGP). But Sanger method is too expensive and takes too long time, such that HGP project spent 3 billion dollars over fifteen years[5]. Untill next-generation sequencing (NGS), also named high-throughput sequencing, technologies generated, the cost of vast sequencing became comprehensive and really acceptable. 454 pyrosequencing[6], illumina (Solexa) sequencing[7], SOLiD sequencing[8] are three mainly applied popular methods. Meanwhile the third generation nanopore DNA sequencing has appeared[9]. Owing to technology development, sequencing cost per genome exponential decrease from 1 million dollars in 2008 to just 1 thousand now[10]. Encouragingly, the cost will keep dropping, and sequencing would become as simple as reading information from a hard disk or compact optical disk.
'+ '<img src=" " />
" />
Fig.3. The history of DNA sequencing technology progress.
On the other read, writing information physically into DNA molecules depends on the chemical synthesis of artificial DNA sequences. Currently, chemical synthesis of short nucleic acids has been extensively used as primer, probe and so on. The process is implemented as solid-phase synthesis using phosphoramidite method[11] and phosphoramidite building blocks derived from protected 2’-deoxynucleosides (dA, dC, dG, and T), ribonucleosides (A, C, G, and U), or chemically modified nucleosides. (Figure 4). Regrettably, we still can’t easily synthesize longish DNA segments or some possessing special second structures or high GC-content now. Although oligonucleotide synthesis has been proposed very early in 1955[12], DNA synthesis is much expensive than sequencing, even innovative DNA synthesis company Twist Bioscience still costs 0.04 cent of every base while just 1 cent in reading 1 million bases.
'+ '<img src=" " />
" />
Fig.4. Synthetic cycle for preparation of oligonucleotides by phosphoramidite method[13].
Considering the above situation, notwithstanding current DNA storage demand a large of investment that per megabyte were estimated at $12,400 to encode data and $220 for retrieval[14]. It is already accessible for us. What we need to care is how to design the connection between DNA sequence and digital information. In our project we develop an innovative software Bio101 to solve the problem.
'+ 'Project abstract
'+ 'Towards creating a platform for information storage in synthesized DNA, our team built the user-friendly website tool Bio101 for transformation between DNA sequences and computer files. We replace ternary transformation process[14] into quaternary system to accelerate the code speed in order to fulfill demand of web-app. Meanwhile, we still keep the randomness of DNA sequences to avoid functional gene segments.
'+ '<img src=" " />
" />
Fig.5. The design of Bio101 for transformation between DNA sequences and computer files.
There are five steps in this process including compression, encryption, bit-to-nt conversion, indexing and validation. (Fig.5) This coding tool can create a convenient DNA information workflow, so researchers can choose any files they want and focus on synthesizing DNA. The surprisingly simple idea has the potential to reshape the global face of data storage in the not-too-distant future, and our work contributes to practical areas can accelerate the step to success.
'+ 'Responding to demand of information edit, new module of system introduces CRS-9’s proposal for segment substitution. Since former design regards and scrambles whole files as whole, it’s necessary to reorder our workflow, put fragmenting into the first step, here is our new design:
'+ 'New design provides independence to every segment, therefore CRS-9 could target it and destroy it in theory without influencing other information.Even thought, new process reduces power of encryption, we still keep randomness.
'+ 'First version is for data archiving, and second one is for data edit. First one collects and utilizes experience from past, and the second one looks forward and embrace future.
'+ 'Reference
'+''
'+
- '+
'
- [1] Goldman N, Bertone P, Chen S, et al. Towards practical, high-capacity, low-maintenance information storage in synthesized DNA[J]. Nature, 2013, 494(7435): 77-80. ' + '
- [2] Bornholt J, Lopez R, Carmean D M, et al. A DNA-based archival storage system[C]//Proceedings of the Twenty-First International Conference on Architectural Support for Programming Languages and Operating Systems. ACM, 2016: 637-649. ' + '
- [3] Grass R N, Heckel R, Puddu M, et al. Robust Chemical Preservation of Digital Information on DNA in Silica with Error‐Correcting Codes[J]. Angewandte Chemie International Edition, 2015, 54(8): 2552-2555. ' + '
- [4] Sanger F, Nicklen S, Coulson A R. DNA sequencing with chain-terminating inhibitors[J]. Proceedings of the National Academy of Sciences, 1977, 74(12): 5463-5467. ' + '
- [5] Lander E S, Linton L M, Birren B, et al. Initial sequencing and analysis of the human genome[J]. Nature, 2001, 409(6822): 860-921. ' + '
- [6] Margulies M, Egholm M, Altman W E, et al. Genome sequencing in microfabricated high-density picolitre reactors[J]. Nature, 2005, 437(7057): 376-380. ' + '
- [7] Bentley D R, Balasubramanian S, Swerdlow H P, et al. Accurate whole human genome sequencing using reversible terminator chemistry[J]. nature, 2008, 456(7218): 53-59. ' + '
- [8] Valouev A, Ichikawa J, Tonthat T, et al. A high-resolution, nucleosome position map of C. elegans reveals a lack of universal sequence-dictated positioning[J]. Genome research, 2008, 18(7): 1051-1063. ' + '
- [9] Clarke J, Wu H C, Jayasinghe L, et al. Continuous base identification for single-molecule nanopore DNA sequencing[J]. Nature nanotechnology, 2009, 4(4): 265-270. ' + '
- [10] Kedes L, Liu E T. The Archon Genomics X PRIZE for whole human genome sequencing[J]. Nature genetics, 2010, 42(11): 917-918. ' + '
- [11] Reese C B. Oligo-and poly-nucleotides: 50 years of chemical synthesis[J]. Organic & biomolecular chemistry, 2005, 3(21): 3851-3868. ' + '
- [12] Michelson A M, Todd A R. Nucleotides part XXXII. Synthesis of a dithymidine dinucleotide containing a 3′: 5′-internucleotidic linkage[J]. Journal of the Chemical Society (Resumed), 1955: 2632-2638. ' + '
- [13]
 ' +
'
' +
' - [14] Goldman N, Bertone P, Chen S, et al. Towards practical, high-capacity, low-maintenance information storage in synthesized DNA[J]. Nature, 2013, 494(7435): 77-80. ' + '
},
{
name:"Design",
img:" ",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['The optimization of the front-end','The design of back-end','Framework of our website'],
content: +
",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['The optimization of the front-end','The design of back-end','Framework of our website'],
content: +
'To realize a fluent and efficient DNA-based information storage system, great efforts have been devoted to designing of its web system.
' + 'The optimization of the front-end
' +'Website based' +'
Due to the rapid development of network, web is now used extensively throughout the whole world. Meanwhile, website is more likely to be used without installing any app. Most importantly, website is compatible with different equipment and systems such as windows, mac os, linux and so on. So we developed our software based on website. In order to ensure the stability and high efficiency, we accomplished all computational calculating on our server and provided users an API to download the final result.
'+'User-friendly Interface' +'
The interface of our webpage is concise. We have two main buttons on our webpage—encode and decode, which can complete users’ demand of uploading, transforming and downloading files. Users can easily familiarize the operation of our software, and use our software to do more things they want. To develop a cross-platform software, HTML, CSS, bootstrap, and jQuery are integrated into the framework of the present software. The webpage is a humanized and beautiful design, and quick in response.
' + '<img src=" "/></br>Fig.1.The interface of Bio101.
"/></br>Fig.1.The interface of Bio101.
'Clear operation flow' +'
Our website has a clear operation flow as the following figure. When a user starts to encode a file, he or she will submit a file and a code as token to encrypt the file. The file will be compressed and encrypted after stored in our server. After that, process goes to encode it and user will go to the ‘Download’ page after the encoding process. User can choose txt, fasta or SBOL-xml format to download the final DNA sequences. As for decoding, user will submit a file with DNA sequences which are encoded by our software and a code which is set when encoding the file. Decoding will start after the file being stored in our server. Then, the file will be decrypted by token and decompressed. After that, website will skip to ‘Download’ page, so user can download the decoded file.
' + '<img src=" "/></br>Fig.2.Design process of Bio101.
"/></br>Fig.2.Design process of Bio101.
The design of back-end
'+'Rigorous process designed' +'
Before the file transformed to DNA sequences, a compression step is needed, which can help decrease the length of synthesized DNA sequences to reduce the consuming of money and time. Thanks for Martin Scharm’s blog “<a href="https://binfalse.de/2011/04/04/comparison-of-compression" target="_blank" style="color:blue;">Comparison of compression</a>” systematically analyzed different compression algorithms. We choose bzip2 to compress file. In consideration of a good information storage system, encrypting the message is essential. So after compression process, we use a fast cryptographic random number generator(ISAAC) to encrypt the compressed file to minimize the safety cases so as to keep the information secret. Then, we need to transform the binary numbers to DNA sequences. In order to store various large pieces of information, we fragment the long DNA sequence into pieces and add each new sequence address code and check code, which help to rebuild the sequence with errors.
' + '<img src=" "/></br>Fig.3.The process of encoding and decoding.
"/></br>Fig.3.The process of encoding and decoding.
'Different file formats supported' +'
Our software supports the transforming of all formats of files, including jpg, pdf, mp3, etc. So users can store all kinds of computer files in DNA. On the other hand, we provide different formats of recording DNA sequences for users to download, including txt, xml, SBOL, etc. Users can easily use these different formats of files to do more things.
' +'C language and Python Combined' +'
C language has high execution efficiency, crossing platform application, etc. Whereas Python holds a great promise for conciseness, extensibility, abundant library, etc. So, the two are combined in Bio101 to form an ideal environment. The encryption and bit2nt parts are handled in C language while the rest is in Python, to guarantee the efficiency and the extensibility of the program.
' + '<img src=" "/></br>Fig.4.Bio101 combine python and C programming language.
"/></br>Fig.4.Bio101 combine python and C programming language.
Framework of our website
'+'Web Programming with Django' +'
The front-end and back-end are separated, which are connected with Django web framework. Django is a high-level Python Web framework that facilitates rapid development and clean, pragmatic design. It’s also a free and open source. When users upload a file to the server-side interface, the back-end works, and then a DNA sequences file will be returned for the users to download. Developers can easily improve the codes in the back-end without worrying about any conflict with present front-end codes.
' +
},
{
name:"Features",
img:" ",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Why do we choose DNA?','What do Bio101 develop or improve as a DNA information storage system?','Reference'],
content: +
",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Why do we choose DNA?','What do Bio101 develop or improve as a DNA information storage system?','Reference'],
content: +
'Why do we choose DNA?
' + 'DNA, as the epochal information storage medium, has many amazing features, [i.e.,] high-density, massive, high-stability, easy-access and free-maintenance.
'+'High-density and massive' +'
DNA information storage technology will be a landmark in the future-oriented storage technology. We believe that DNA is an incredibly high-density and massive storage medium. At theoretical maximum, DNA can code two bits per nucleotide(nt) or 455 exabytes pergram of ssDNA[1] . Bio101 can transform 200MB files once because of the length of indexes now.
' + '<img src=" " />
" />
Fig.1. The history of the data storage.
'High-stability' +'
DNA is a high-stability molecule, with a remarkable long life-span even in suboptimal environments, making it an ideal storage material. Indeed, more than 80% of the woolly mammoth (Mammoths primigenius) genome, comprising 3.3 billion nt, remains readable despite the fact that this species has disappeared from the planet at the end of the Pleistocene (10,000 years ago).
' + '<img src=" " />
" />
Fig.2.Extracting and reading DNA from Mammoth fossil.
'Easy-access and free-maintenance' +'
Molecular biology now provides us with the tools to cut (restriction endonucleases), paste (DNA ligase) and copy (PCR) DNA as we might do with the text of a word document. DNA also does not require frequent maintenance. When reading, DNA storage technology will not encounter compatibility problem.
' + 'What do Bio101 develop or improve as a DNA information storage system?
' + 'When we were working on our Bio101, we found that CUHK[2] also developed a similar project in 2010. So we compared our project with CUHK’s project and the results are shown in Table1:
' + '<img src=" " />
" />
Tab.1. The comparison of two projects.
And more details about features of Bio101 are shown as follows:
'+'1. Higher compression' +'
We use bzip2 algorithm to compress the file, which accelerated the code speed in order to fulfill demand of web-app. Through the Table2[3], we can find that bzip2 has a higher compression ratio than other compression algorithms which means less storage space and less bases, so we can save the cost of DNA synthesis.
'+ '<img src=" " />
" />
Tab.2. Comparison of several kinds of compression software.
'2. Securer encryption' +'
We use ISAAC[4]—an encryption algorithm as well as a fast cryptographic random number generator to ensure that the bases appearing in consequential DNA sequence are almost random and reduce the homopolymers.
'+'3. New conversion for bit-to-nt' +'
We transform one byte of bits into four bytes of A (00), T (11), C (01), G (10) so that the coding efficiency of our system improves greatly. The transform rules are showed on Table 3.
'+ '<img src=" " />
" />
Tab.3. Encoding rules.
'4. Higher fault tolerancet' +'
Our system involves readings of 200 bp long shifted by 50 bp to ensure four-fold[5] coverage of the sequences so we can always get the accurate information from the redundant sequence. Meanwhile, we add indexes to the sequence, which contains address code and check code. It will help us know the location of sequence in a file and examine whether the sequence goes wrong or not during the synthesizing, storing or sequencing progress.
'+ '<img src=" " />
" />
Fig.3. Fourfold redundancy and index to improve fault tolerance.
'5. User-friendly design' +'
Interface: We design a webpage that allows users to experience our software, through which users can upload any format file they want to encode or the file including DNA sequences to decode easily and quickly download the DNA sequence files generated or the original files conveniently.
' + '<img src=" " />
" />
Fig.4.User-friendly interface of Bio101.
Compatibility: Bio101 can work stably in a number of multi-task operating systems without frequent crashes. Also users can choose any file they want and then focus on synthesizing DNA by Bio101. The software is accessible for any device and platform.
' + 'Extendable: The evaluation criteria of a program should depend on its portability. Our code is open source, and we provide four APIs for developers to reuse the function of our software—ISAAC64 random encryption algorithm, bit-to-nt conversion, nt-to-bit conversion and Blast.
' + '<img src=" " />
" />
Fig.5.Conversion any file by Bio101 on different devices and platforms.
Reference
'+''
'+
- '+
'
- [1] George M. Church. Yuan Gao, Spiram Kosupi. Next-Generation Digital Information Storage in DNA. Science, online August 16, 2012 ' + '
- [2] https://2010.igem.org/Team:Hong_Kong-CUHK. ' + '
- [3] http://www.cnblogs.com/langzou/p/5823285.html. ' + '
- [4] http://burtleburtle.net/bob/rand/isaacafa.html. ' + '
- [5] Goldman N, Bertone P, Chen S, et al. Towards practical, high-capacity, low-maintenance information storage in synthesized DNA. [J]. Nature, 2013, 494(7435):77-80. ' + '
},
{
name:"Modeling",
img:" ",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Encoding','Decoding','Example'],
content: +
",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Encoding','Decoding','Example'],
content: +
'Our project is mainly centered on how to improve the storage density and avoid the mistakes that may occur during the process of designing a stable, high-density DNA information storage system. There are two main technological processes, encoding and decoding, in the system.
' + '<img src="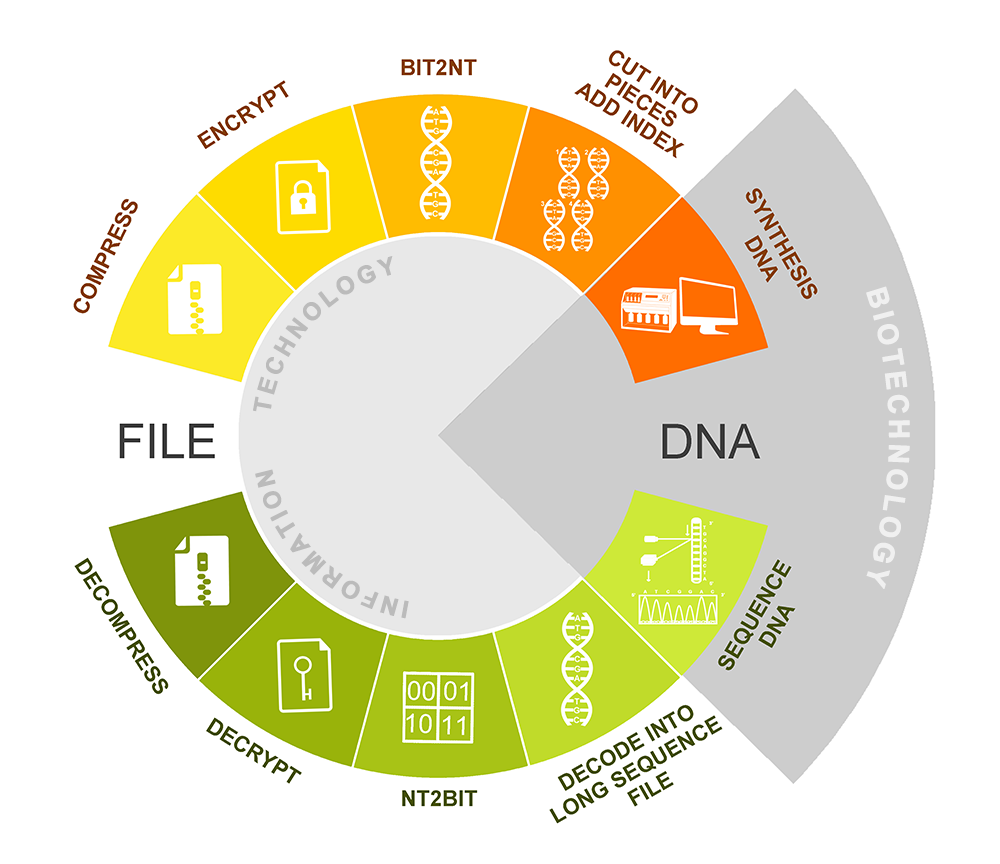 " />
" />
Fig.1.system flow diagram.
Encoding
' + 'Compression: ZIP algorithm
' + 'We used bzip2 algorithm which renowned as a high-quality data compression algorithm to compress the file. It typically compresses files to within 10% to 15% of the best available techniques, whilst being around twice faster at compression and six times faster at decompression. After this process, we get a bz2 compression file.
' + 'Encryption: ISAAC encryption algorithm
' + 'Next, we use ISAAC encryption algorithm to encrypt the bz2 file. After you input your own password, ISAAC generates a pseudorandom stream of bits (a keystream). As with any stream cipher, these can be used for encryption by combining it with the plaintext using bit-wise exclusive-or; decryption is performed the same way (since exclusive-or with given data is an involution). After this process, we can get a sufficiently random binary file.
' + '<img src="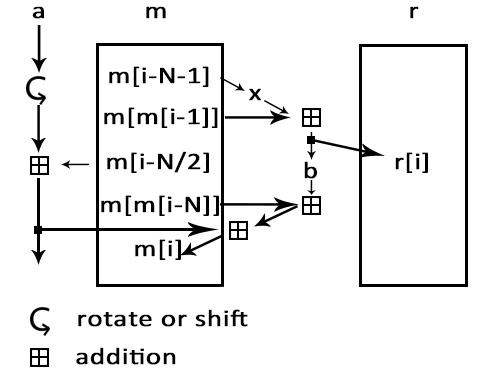 "/>
"/>
Fig.2. encryption process.
Bit-to-nt conversion: quanternary system
' + 'In bit-to-nt conversion process, we use the idea of the quaternary system. As we all know, there are four basic groups—A, T, C, G, and it can be seen as a quaternary system. In bit-to-nt conversion, one byte of bits converts into four bytes of A, T, C, G, using the scheme illustrated in Table 1.
' + '<img src="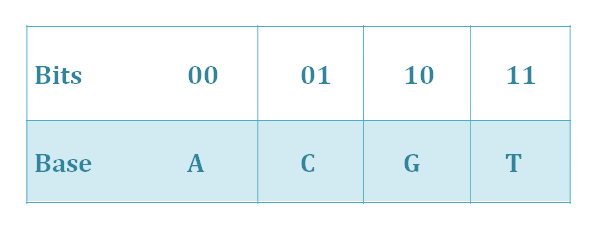 " />
" />
Tab.1.Bit-to-nt conversion.
We read out the binary string S0 of the binary file generated in the last process. Use bit-to-nt conversion to convert S0 into a DNA string S1. We get a long DNA sequence.
' + 'Fragmenting & indexing
' + 'Write len( ) for the function that computes the length of a string, and define n=len(S1). Represent n in base-4 and prepend ‘0’s to generate a string S2 of quaternary such that len(S2)=15. Form the string concatenation
' + 'S4=S1.S3.S2(1)
'+ '(the symbol ‘ . ’ means the connection of two srings)
'+ 'where S3 is a string of at most 49 ‘ 0 ’s chosen so that len(S4) is an integer multiple of 50.
'+ 'Convert S2 and S3 to DNA strings S2’ and S3’using the scheme illustrated in Table 2.
'+ '<img src=" " />
" />
Tab.2.Quaternary-to-nt conversion.
Recode the DNA string S3’.S2’ from the second character to S2’’ with repeated nucleotides as few as possible using the scheme illustrated in Table 3.
'+ '<img src=" " />
" />
Tab.3.Recoding table.
From
'+ 'S5=S1.S2’’(2)
'+ 'Even-odd check
' + 'Define N=len(S5). Split S5 into overlapping segments of length 200 nt, each offset from the previous by 50 nt. This means there will be (N/50)-3 segments, conveniently indexed
'+ 'i = 0,1,......,(N/50)-4(3)
'+ 'segment i is denoted Fi and contains (DNA) characters
'+ '50i,......,50i+199(4)
'+ 'of S5. If i is odd, reverse complement Fi.
'+ 'Let i4 be the base-4 representation of i, appending enough leading ‘0’s so that
'+ 'len(i4) = 12(5)
'+ 'Recode i4 using the same strategy in Table 2 & Table 3 above, and i4 is represented in nt.
'+ 'Compute P as the sum(mod 4) of the even-positioned quaternary in i4.
'+ 'P = ([i4]2+[i4]4+[i4]6+[i4]8+[i4]10+[i4]12 ) mod 4(6)
'+ 'P acts as a ‘parity quaternary’—analogous to a parity bit—to check for errors in the encoded information about i.Form the indexing information string
'+ 'IX = i4.P(7)
'+ '(comprising 12+1=13 nt)
'+ 'Append the DNA-encoded version of IX to Fi to give indexed segment Fi’.
'+ 'Then form Fi’’ by prepending A or T and appending C or G to Fi’ —choosing between A and T, and between C and G, randomly if possible but always such that there is no repeated nt. This ensures that we can distinguish a DNA segment that has been reverse complemented during DNA sequencing from one that has not—the former will start with G|C and end with T|A; the latter will start A|T and end C|G.
'+ 'The segment Fi’’ are synthesized as actual DNA oligonucleotides and stored, and may be supplied for sequencing.
'+ '<img src="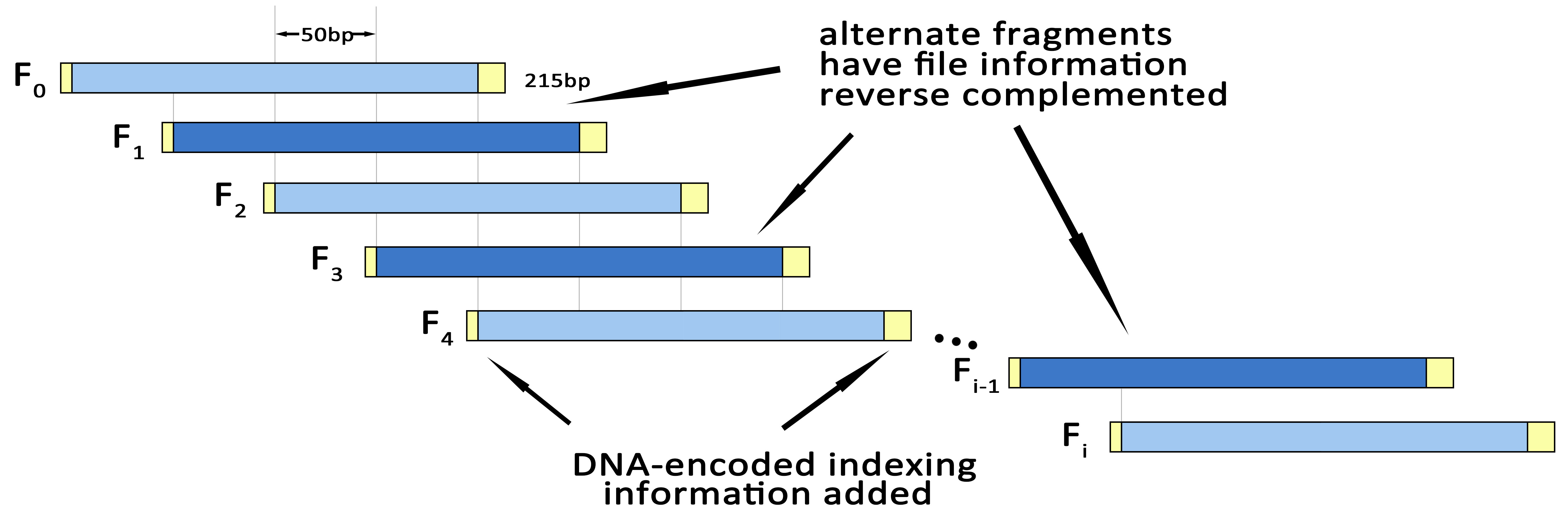 " />
" />
Fig.3.Fragmenting & Indexing.
Safety testing: BLAST
' + 'In order to check whether the sequences we generated are safe, we use BLAST to compare the sequences with the Biobricks database. We use all the Biobricks sequences to establish a FASTA format file, and use BLAST to format it to set up a BLAST database. Then through local BLAST, we compare the sequences generated with the Biobricks sequences to confirm that the sequences are out of bio-function.
' + 'Decoding
' + 'Recognition of the front and the end of a sequence
' + 'Reverse complementation during the DNA sequencing procedure (e.g. during PCR reactions) can be identified for subsequent reversal by observing whether fragments start with A|T and end with C|G, or start with G|C and end with T|A.
' + 'Reading and check of index
' + 'With these two ‘ orientation ’ nt removed, the remaining 213 nt of each segment can be split into the first 200 ‘ message ’ nt and the remaining 13 ‘indexing’ nt. Decode the ‘ indexing ’ nt to quanternary using the reverse of the encoding tables in in Table 2 & Table 3 above, and use P to check the correctness of i4.
' + 'Correction of segments through four-fold redundancy
' + 'Use i to determine the location of each fragment. Split each fragment into segments of length 50 nt. As we provide a four-fold redundancy, we compare the 50-nt segments which are in the same location and inaccurate bases can be corrected by using majority vote. Connect all the segments to a whole DNA sequence.
' + 'Decoding, decryption and decompression
' + 'Decode the DNA sequence by using the reverse of the encoding table in Table 1 above, and use ISAAC to decrypt it, and then decompress. We get the original file.
' + 'Fuzzy matching with high-throughput sequencing
' + 'Errors introduced during DNA synthesis, storage or sequencing could lead to various nt insertion, deletion or substitution. Recovery of information from fragments with such errors may be possible via PCR amplification and high-throughput sequencing.
' + 'Example
' + 'In order to make our encoding process more understandable and clearer, we show an example here.
'+ 'With a given text file, we read out its binary file, then compress it with bzip2 algorithm, and use a pseudorandom stream of bits to encrypt it. Then use bit-to-nt conversion to convert the binary numbers to bases. Shown in Figure 4.
'+ '<img src=" " />
" />
Fig.4.Schematic of DNA information storage system.
The computer file (in any format, e.g. text) shown in (a) is read in binary format (b), and use bzip2 to compress it (c). Then through ISAAC encryption algorithm use pseudorandom stream of bits (d) and exclusive-or to generate a new binary string (e). Then one byte of bits converts into four bytes of A, T, C, G (e).
'+ '1. Towards the text file “IGEM UESTC-SOFTWARE”, its binary coding is
' + '<img src=" " />
" />
2. After compressing, its compressed coding is:
' + '<img src=" " />
" />
3. With the pseudorandom stream of bits that ISAAC64 generated (password: uestc-software):
' + '(lack of data, data need to be caculate)
'+ 'Using XOR operation:
'+ 'S’ XOR (pseudorandom stream of bits)
'+ 'We get a new binary string S0:
'+ '<img src=" " />
" />
4. Using the scheme illustrated in Table 1, we convert the bytes of S0 into bases—A, T, C, G.
' + '<img src=" " />
" />
5. n=len(S1 )=3376, which is 310300 in base-4. So:
' + '<img src="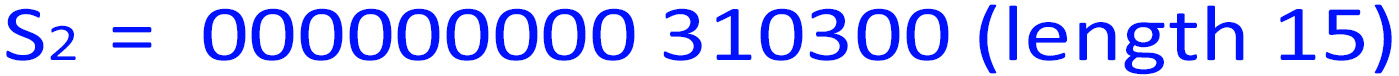 " />
" />
<img src="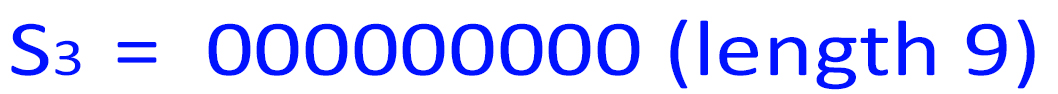 " />
" />
len(S4 )=len(S1 )+len(S2 )+len(S3 ) = 3376 + 15 + 9 = 3400 = 50 * 68
'+ '6. Using the scheme illustrated in Table 2, convert S2 and S3 to DNA:
' + '<img src=" " />
" />
Recode the DNA string S3’ . S2’ from the second character to S2’’ with repeated nucleotides as few as possible, using the scheme illustrated in Table 3.
'+ '<img src=" " />
" />
7. N=len(S5 )=3400. We split S5 into overlapping segments of length 200 nt, each offset from the previous by 50 nt.
' + 'S5 will be split into overlapping segments Fi of length 200 nt for
'+ 'i=0......(3400/50)-4, i=0,1,......,64
'+ 'With overlapping parts underlined for illustration, F0 to Fi are:
'+ '<img src=" " />
" />
8. Only i=1,3,...,63 are odd, so Fi is reverse complemented:
' + '<img src=" " />
" />
9. For i=0,i4=000000000000 (length 12) and the sum (mod 4) of the even-positioned quaternaries of i4 is
' + 'P = (0+0+0+0+0+0)(mod 4) = 0
'+ 'For i=1,i4=000000000001
'+ 'P = (0+0+0+0+0+1)(mod 4) = 1
'+ 'For i=0,IX=i4.P=0000000000000
'+ 'For i=0,IX=i4.P=0000000000011.
'+ 'So:
'+ '<img src=" " />
" />
11. Prepend A|T and append C|G (in this example we have three random choice, at the front of F0’’, the end of F0’’, and the end of F1’’):
'+ '<img src=" " />
" />
},
{
name:"Validation and testing",
img:" ",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Dry-lab testing','Wet lab validation'],
content: +
",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Dry-lab testing','Wet lab validation'],
content: +
'Having developed our DNA information storage system, it is important to validate our software performs its intended function. We did thorough dry-lab testing and wet-lab validation, in which we tested the efficiency and safety of our system and successfully restored our file in synthesized DNA sequences.
' + 'Dry-lab testing
' + 'We chose different formats of files as test cases to test the efficiency and fault tolerance of our system. We must confirm that if certain bases in the sequence change, it can still be restored to the original file. We take a text file” Bio101 description” to clarify our validation.
' + '<img src=" "/>
"/>
<img src=" "/></br>Fig.1.Software test flow chart.
"/></br>Fig.1.Software test flow chart.
'Step 1'+'
We encode the file “Bio101 discription.txt” and get DNA sequences.
'+ '<img src=" "/>
"/>
'Step 2'+'
We modify the DNA sequence, including add, delete the base, move the base position, and test whether the software can also restore the original file.
'+ 'For example, we deleted line 10, and added three AGCT repeats at line 15.
'+ '<img src=" "/>
"/>
'Step 3'+'
We decoded the modified DNA sequence and got the original file. Thus, it proved the fault tolerance of our software.
'+ 'Afterwards, we use Blast to verify the safety of the DNA sequences generated.
'+ '<img src=" "/>
"/>
The result shows that there is no encoded DNA sequence matching the any DNA sequence in BLAST. So we can believe that the sequences generated by Bio101 are safe.
'+ 'After safety validation, we make data analysis of the DNA sequences files generated, including the contents of each base, the length of repeated nucleotides and the length of repeated nucleotides fragment (such as TAAAAAC or ACGT ACGT ACGT).
'+ '<img src=" "/></br>Fig.2.Analysis report of encoding sequences.
"/></br>Fig.2.Analysis report of encoding sequences.
In this report, we can see that the number of four bases in the sequence is substantially equal. And sequences of continuous repeats are almost non-existent.
'+ 'Wet lab validation
'+ 'Besides software testing, wet lab validation is also needed.
'+ '<img src=" "/></br>Fig.3.Wet lab validation flow chart.
"/></br>Fig.3.Wet lab validation flow chart.
We transformed the chosen file, “sSBOLv.svg”, to DNA sequence file. Going through thorough data analysis and safety confirmation, we connected a biotech company to help us synthesize the DNA sequences.
'+ 'DNA sequences carrying our file information should be stored in host cells. We chose E.coli TOP10 to store plasmids. The synthesized DNA sequences were transformed into pUC47.
'+ '<img src=" "/></br>Fig.4.Plasmids transformation.
"/></br>Fig.4.Plasmids transformation.
After a week of storage, we took out the sample for sequencing. In order to improve the accuracy of sequencing, we used PCR amplification and high-throughput sequencing to accomplish our work. With regard to the sample, we used PCR amplification to generate more sequences at first. Then used E. coli to copy the sequences for high-throughput sequencing.
'+ 'In the end, we uploaded the DNA sequences file to our software and decoded them. At last, we achieved the original file perfectly.
'+
},
{
name:"Future",
img:" ",
mediaSrc:"https://2016.igem.org/Team:UESTC-software/Future",
catalogue:['Improve the core algorithms','Find a better encoding method','Enable random access and information rewriting','Decrease the cost of synthesize the sequences','Experiment further to verify the feasibility'],
content: +
",
mediaSrc:"https://2016.igem.org/Team:UESTC-software/Future",
catalogue:['Improve the core algorithms','Find a better encoding method','Enable random access and information rewriting','Decrease the cost of synthesize the sequences','Experiment further to verify the feasibility'],
content: +
'Bio101 should not only be a software created to join in the competition, but also a tool with an ultimate goal to contribute to the revolution of information storage technology. We have done our best to design, implement and test Bio101 this summer and we will pay further efforts to improve our software both in program coding and practical application.
'+ '<img src=" "/>
"/>
Fig.1.We will mainly improve Bio101 from five aspects.
Improve the core algorithms
'+ 'So far, we have chosen ZIP algorithm to compress the file, which has greatly accelerated the code speed in order to fulfill the demand of the web-app. However, although ZIP is the most popular compression algorithm, its efficiency is not good enough. Therefore, we are seeking for a better compression algorithm for achieving a better combination between speed and cost.
'+ 'Find a better encoding method
'+ 'Currently, the encoding method we use may cause some homopolymers (i.e., repeated consecutive bases) and restriction enzyme cutting sites to exist in the DNA sequences we generate, which can lead to some errors during the synthesizing and storing process. So, we need to find a better method to avoid homopolymers and restriction enzyme cutting sites.
'+ 'Enable random access and information rewriting
'+ 'If you only want to get a small specific part of the information using the existing version of the Bio101, you need to decode all of the DNA sequences before you can read that part, so does it to modify and rewrite the information in arbitrary locations. It can result in a large cost both of time and money. Therefore, we want to enable random access to data blocks and rewriting of information stored at arbitrary locations within the blocks.
'+ '<img src=" "/>
"/>
Fig.2. Bio101 build a bridge between computer files and DNA sequences.
Decrease the cost of synthesize the sequences
'+ 'We also considered problems about application which is very important for Bio101 to spread and develop. Not only information technology we focused but also biotechnology. Our software is not an isolated system, but a bridge between the computer world and the real world.
'+ 'Although the prospect of DNA information storage is very broad, the biggest obstacle to its promotion is the costly price. We provide four-fold coverage to control redundancy, which adds to the burden of money beyond all doubt. Since the limit of current DNA technology, we can’t cut synthesizing and sequencing cost directly, but we can optimize our algorithm to decrease redundancy to shorten the DNA sequences and then reduce the cost.
'+ 'Experiment further to verify the feasibility
'+ 'In consideration of time and money, we used a small file as the test object in our test and validation. Although we got the expected result, we still considerate in our future plan to do more experiments to verify our system and learn the storage density and maximum capacity.
'+ 'In spite of these problems need to be solved, we believe that our information storage system has a good application prospect for its web-based design, convenient use and high capacity. Once the current biotechnology of synthesizing and sequencing DNA achieve a breakthrough, our system could be widely used in everywhere. And if we can easily store and read information in DNA anywhere at any time, the whole world would be changed. So we say, we are witnessing a great revolution, and we are glad to be one of it.
'+
},
{
name:"Extra Work",
img:" ",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Description','Visualization','Design','Modeling','The finite state projection (FSP) algorithm','Future'],
",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Description','Visualization','Design','Modeling','The finite state projection (FSP) algorithm','Future'],
content:'Bio1024
' + 'Description
'+'Background'+'
In synthesis biology, a hot issue is the efficient building of genetic circuit. As an essential model, the circuit provides synthetic biologists a simulation of the gene behavior in vitro. This approach to manipulate gene network is possible because of large calculation quantity. Our software, Bio1024, provides a resultful method to conquer the defect. Bio1024 picks an advanced algorithm, FSP, to decrease calculation quantity with a set of visualized components. Compared with the existing similar model, we improve the accuracy greatly and optimize the visualized components in detail. We offer a more various platform to estimate genetic circuit so that research workers get closer to the future of biological synthesis.
'+'Overview'+'
In synthesis biology, it is tough to build the circuit for many beginners or people unprofessional while it’s fundamentally important. Thus we establish a set of system, which ought to make the circuit available to everyone. A set of visualized components are built to dumb down operations, likewise the backstage supporter’s predicting algorithm possesses a nice accuracy, which constitute the software’s framework. In detail, we promise users self-defining parameters of components, colors and connections changed, and variable component substitution. Users get access to the software through four steps, importing circuit, setting up parameters, submitting and acquiring the estimation. The import ought to be an integrated circuit with well-defined parameters, the responses from the backstage supporter is a curve graph, in which the system’s steady state varies as the numbers of the selected states growing at a given time.
'+ 'The entirety encompasses the simplification while padding the details at the framework of visualization. Also we pick the FSP algorithm to excavate the accuracy after taking a view of the existing models. Integrating the two sections and optimizing details, we hold a promise to consummate the project.
'+'Innovation'+'
Bio1024 offers multiple functions, which will bring more convenience to synthetic biology researches in the future.
'+ 'Visualization
'+ 'Bio1024 provides a visual interface, and defines promoters, insulators, and other components. Drag these components to designated area and connect them to construct genetic circuits.
'+ 'User-defined parameters
'+ 'Bio1024 provides self-defining parameters of corresponding components as while as construct genetic circuits, which helps to predict distribution of probability in steady states based on the parameters input. Compared with precious items which can only call parameters from database, this is a highlight. In addition, users can change components’ indexes and their colors to distinguish. In this way, users can learn about the structure clearly.
'+'Accuracy enhancement'+'
Many teams have put forward some prediction algorithms, such as the prediction mechanism based on the macro level raised by SYSU, which uses concentrations to measure matters’ concentration in the system. But we use a microstate numerical prediction mechanism on account of chemical master equation. Bio1024 adopts the number of each kind of molecules to describe states of system. The output of software is the probability graph that shows the system may be in certain states after a certain time.
'+ 'Design
'+'Demand analysis'+'
Construction of genetic circuits has always been a hotspot as well as a difficulty in synthetic biology. Thus we design our software aiming at its complexity and unpredictability. We focus on simplifying the process of circuits constructing, providing high-precision prediction algorithms, and allowing user-defined parameters.
'+ 'Here we introduce our front-end layout by use-flows:
'+ '<img src=" " />
" />
Fig.1 Home page
Enter interactive interface and select components needed.
'+ 'Drag icons of different parts to the corresponding positions in circuits frame and connect them to construct a rudiment.
'+ '<img src=" " />
" />
Fig.2 Design circuit
<img src=" " />
" />
Fig.3 Define parameters and properties of components by oneself
Wait for a while and get the output graph of the software after finishing input steps. This result shows the evolution of steady states when the number of selected states increasing at a particular time.
'+ 'Users can download and save the designed circuit and its corresponding output. The formats provided are .png and. svg.
'+ 'Above is the front-end design of our software. We adopt FSP algorithm based on the chemical master equation as the background core algorithm. Specific procedures are as follows:
'+ 'Back-end gets parameters from the front-end, including models of circuits and original parameter settings for each component.
'+ 'Establish chemical master equations of the system to get each reaction matrix. Select a particular moment, adopt FSP algorithm expanding the scope of the selected state gradually until the result reaches accuracy requirements.
'+ 'Simulation and prediction of the system are plotted and returned to users.
'+ 'The idea of software design is to simplify the process of designing genetic circuits, making it easy to operate and modifiable.
'+ 'Modeling
'+ 'Mathematical model of Bio1024 is based on discrete chemical master equation(CME) and we explore the finite state projection algorithm as the main solving method to analyze stochastic gene regulation and improve accuracy of CME.
'+ 'Basic theorem'+
'Single Linear Expression Of Discrete Chemical Master Equation'+
'The CME describes the gain and loss of probability associated with each state due to chemical reactions. The chemical reaction can be thought as a jump process that bring the system from one combination of molecular species’ copy number to a different combination of molecular species’ copy number once a reaction occurs. The most familiar form of a master equation is a matrix form:
'+ 'We assume a system with N molecular specie:and M chemical reactions:
'+ 'We also define a vector v as reaction rate constant:and denote the copy number of i-th molecular species as. The combination of the copy numbers at time t is a vector of integers and is denoted as:
'+ 'We call x(t) the microstate of the system at time t. The probability for the system to be in state x(t) is P(x, t). The rate of the reaction that connects state to state is determined by the intrinsic reaction rate constant , and the copy numbers of relevant reactants, which is given by the state :
'+ 'However, more than one reaction may connect to , we have the overall reaction rate that brings the system from to as:So the discrete chemical master equation can then be written as:And we can write this equation in a more compact form:
'+ 'A is the rate matrix formed by the collection of all A is also the matrix describing the transition rates(also known as kinetic rates or reaction rates). The elements of A are given as:
'+ 'The finite state projection (FSP) algorithm
'+ 'The CME dimension can be extremely large or infinite, so approximations are needed. The FSP is a numerical method to approximate the solution of the CME and compute the error of this approximation. The FSP selects a finite set of states as a state space. And the solution of CME beginning at t=0 and ending at t= is the expression:
'+ 'In the case where there is only a finite number of reachable states, the operator is the exponential of , and one can compute the solution:
'+ 'We specify the total amount of acceptable error . If the error is within an acceptable range:, we can accept the result. If not, we’ll add more states to the state space and compute again. Finally, we can get steady state probability graph by plotting state-probability.
'+'Assembled example'+'
Here we give an example to predict for the assembled plasmid-LacI-pTAC-gfp circuit. Each parameter in this model is from the literature: ribozyme-based insulator parts buffer synthetic circuits from genetic context. Each chemical species undergoes production and degradation events in which the population increases or decreases by one molecule at a time. Reactions with propensity function are described by the formula:
'+'Limitations and improvements'+'
In practice there may be many methods of choosing how to add states to the projection. In general, the best methods will utilize knowledge of the stoichiometry of the chemical reactions and avoid including unreachable states. So we propose some improvement ideas about enumerating state space, and the detailed descriptions are in the FUTURE part.
'+'Reference'+'
Future
'+ 'At this present stage, we provided Bio1024 several main functions that users can drag components to build the circuit needed, and define parameters independently. Besides, designed circuit can be download smoothly.
'+ 'During the summer, as we made great effort to design, implement, test, visualization and algorithm improved, Bio1024 has been completed successfully. However, the software still has a very large room for refinement.
'+'Experimental simulation'+'
Bio1024 currently can only simulate through computer, but hasn’t been proved through wet-experiment. So next, what is important for us is to validate the result of computer simulation by wet-experiment, in order to verify the accuracy of the software.
'+'Two-dimensional drag-and-drop'+'
Currently, the visual interface can only realize one-dimensional elements drag-and-drop and modification, that is, all the movements should be linear. However, the limitation is obvious, so we will transform the method to a more optional movement in two-dimensional surface, namely drag and drop in the entire interface, which will be more flexible to meet more demands for design.
'+'Individual community function'+'
We set prospective goal to add community function, which means users can register personal account in the community to save the finished or unfinished work. Benefited from that, documents will be protected from being lost and the next time invocation will be convenient.
'+'Expand the component library'+'
Nowadays our component library has included some basic elements like promoters, insulators, RBS and so on. Though they can combine to form a basic circuit, it cannot satisfy some special demands from users who want to generate circuit with specific function. Therefore, in the next step, we will add more components to facilitate the user to build more complex circuits.
'+'Algorithm improving'+'
We adopted FSP algorithm to solve the Chemical Master Equation for the steady-state probability distribution accurately, which generate smaller error and become more efficient than stochastic simulation algorithm. But we found that a necessary premise for using FSP algorithm is to enumerate and amplify the system state space, which is very difficult to realize only using current algorithm. As a result, we raised several improved algorithms:
'+'Enumeration of State-space.'+'
Given an initial state and predefined system’s maximum amounts of species production.
'+ 'Traverse each response of current state to determine whether the reaction can occur under current state. If possible, the system will generate the responses and arrive a new state.
'+ 'Check whether the new state appeared before, if not, add it to the state set of system state space.
'+ 'Repeat the above operation to all new state until no more new states produced.
' +'Segmentation of State-space'+'
System states can be broken down into disjoint subsets, in which there are links between the internal states. And subsets can be solved separately.
'+ 'Such problems are called “fully divisible”. Given the initial conditions of the biochemical reaction system, any state can be reached from the initial state after a finite number of steps to another State.
'+ 'Although such a system is not entirely separable, but in this case, we can look for a high cohesion and low coupling split in state space: some subsets of the State space will reach the partial steady-state before the whole steady-state. We will follow-up on this approach further and try to understand. We will collect users’ feedback, and perfect our software.
'+
},
{
name:"Extra Work",
img:"",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Description','Design','Features','Future','Reference'],
content:+
'Bio2048
' + '<a href="https://www.youtube.com/watch?v=gDPVQBgcz64" target="_blank"><img src=" " /></a>
" /></a>
Description
'+'Background'+'
Biology and life are tightly interrelated. After investigation (For more details, please view <a href="https://2016.igem.org/Team:UESTC-software/Human_Practices?id=4&index=0" style="color:#3C9CD3;" target="_blank"> Human Practice </a>), we found that huge amounts of people had little biological knowledge base. For instance, base pair, DNA, protein, organelle, cell, tissue, organ, system, individual, population, community, ecosystem, biosphere, these are important concepts in biology. The distance between ordinary people and those is so long that they nearly cannot touch it. Therefore, it’s imperative to spread the biological knowledge of the mass then to improve the quality of life.
'+'Overview'+'
In order to popularize biological knowledge and draw the public’s attention to biology from the basic level, UESTC-Software decided to adopt a more acceptant way to make more people be aware of the subject. We developed an Android game named Bio2048 based on the Grabriele Cirulli’s “2048”, a popular sliding block puzzle game. Instead of the numbers, the blocks are labeled with some common biological patterns, such as gene and protein. All the patterns form a biological ladder. If two patterns with the same biological terms collide while moving, they will merge into one pattern with a new biological term which moves up by one on the biological ladder.
'+ 'Design
'+ 'As we know, the core of the game “2048” is adding adjacent and same numbers by moving fingers in one direction. We took the core into our design and choose 12 elements: basic group, DNA, protein, organoid, cell, tissue, organic, system, individual, population, community, ecosystem, biosphere, to replace numbers. Besides, we hoped the game interface more three-dimensional, it may have some Chinese elements to get close with users and enrich itself. When those ideas came together, we created the game——Bio2048.
'+ '<img src=" " />
" />
Fig .1. Overall Flow Chart
<img src=" " />
" />
Fig.2. Game Interface Flow Chart
'Welcome interface'+'
When users open the game, the welcome interface will appear. You can click “skip” button to go to the main interface. Or, you can choose to wait for 3 seconds, then, the program will go to the main interface automatically.
'+ '<img src=" " />
" />
Fig.3. Welcome Interface
'Main interface'+'
There are three buttons on the main interface: “PLAY”, “PATTERN”, “RULE”.
'+ 'When you click “PLAY” button, the program will go to the game interface.
'+ 'When you click “PATTERN” button, the program will go to the mode selection interface.
'+ 'When you click “RULE” button, the program will go to the rules introduction interface.
'+ 'When you click the return button which comes with the mobile phone two times in series, the program will exit.
'+ '<img src=" " />
" />
Fig.4. Main Interface
'Rules introduction interface'+'
This interface introduces the specific rules of the game. As the picture shows.
'+ '<img src=" " />
" />
Fig.5. Rules Introduction Interface
'Mode selection interface'+'
Users can choose 4*4 or 5*5 board in this interface. Then, the game interface will present the selected board format.
'+ '<img src=" " />
" />
Fig.6. Mode Selection Interface
'Game interface'+'
In the board, you can slide up or down, left or right four directions to make the game go on. “SCORE” shows the scores obtained in the present. “BEST” shows the historical highest score. At the same time, you can choose learning mode to understand the biological meaning of the patterns during the game. When the game finishes, you can choose to play one more again or exit directly.
'+ '<img src=" " />
" />
Fig.7. Game Interface
Features
'+'Simple game operation'+'
The whole game designed for all people. All kinds of interface are introduced clearly. Everyone can easily master the game operation and obtain the overall process of the game.
'+'Original learning mode'+'
We add learning mode to the game. Using custom Toast realize the function that program could prompt words corresponding to the patterns. Users can select the any mode optionally and learn biology playing the game.
'+'Multiple design elements'+'
China red, panda and other elements integrated into the game enrich the game design. These elements not only play the role of beautification, but also increase the fun of the game.
'+ 'Future
'+'Continual popularizing and improvement'+'
After we successfully developed the Android mobile phone game, we uploaded it to application of Tencent and everyone can download to play. Also, interested people can download source code in the GitHub. Not only did we do those, but also used social media platform like QQ, Micro-blog and Wechat to do online promotion. We have got thousands of people’s attention, which means lots of people can learn more about biology by playing our game. During the process, we have gained many precious suggestions, which can help us make our game better one step at a time.
'+ 'We’d like to continue to popularize the game in the future, and get more feedback to make improvement.
'+'Continual communication and application'+'
We applied Bio2048 to education. After working hard, we successfully contacted local schools and remedial classes to help teachers arouse the learning interest of their students. Absolutely, it is an original way to obtain knowledge. Making our game as a real educational tool in class needs more communication with teachers and practice at schools. We are sure that it is useful for students’ learning by visiting more schools.
'+ 'Inspired by the thoughts of applying game to education, we got more ideas about EDUTAINMENT, we will go further and do better.
'+ 'During the summer, we tried these approaches to practice our thoughts and received a good response. We hope our work can really affect the people around to pay attention to the biology. We believe our work can contribute to the learning of students through communication, test and improvement.
'+ 'Reference
'+ '<a href="http://blog.csdn.net/lmj623565791/article/details/40020137" style="color:#3C9CD3;" target="_blank">http://blog.csdn.net/lmj623565791/article/details/40020137
'+
}
],
[
{
name:"Medal Requirements",
img:" ",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Bronze','Sliver','GOLD'],
content: +
",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Bronze','Sliver','GOLD'],
content: +
'Bronze
' + '<img class="small-img" src=" " />
" />
'1. Register for iGEM, have a great summer, and attend the Giant Jamboree.' +'
UESTC-Software team had been signed up for the collegiate track of the iGEM competition as a "software" team. Certainly we had a great summer for our joint efforts and will attend the Giant Jamboree.
' +'2. Meet all deliverables on the Requirements page (section 3), except those that specifically mention parts. ' +'
Our team had completed the deliverables in time, including team wiki, poster, presentation, project attribution, safety forms and judging forms.
' +'3. Create a page on your team wiki with clear attribution of each aspect of your project. This page must clearly attribute work done by the students and distinguish it from work done by others, including host labs, advisors, instructors, sponsors, professional website designers, artists, and commercial services.' +'
This is it! Click Our Attributions Page(), and you can find individual attributions of each one who has made contribution to our project ,including members, mentors and other supporters.
' +'4. Document at least one new substantial contribution to the iGEM community that showcases a project made with BioBricks. This contribution should be equivalent in difficulty to making and submitting a BioBrick part.' +'
This summer we created the software, Bio101, which focused on DNA storage. Having verified all Biobricks, we affirmed that the generated sequence wouldn’t be same as any composition of Biobricks, especially those labeled as dangerous, which proved the randomness and innocuousness of our project.More details will be shown on Project Page().
' + 'Sliver
' + '<img class="small-img" src=" " />
" />
'1. Validate that something you created (art & design, hardware, software, etc) performs its intended function. Provide thorough documentation of this validation on your team wiki. ' +'
We tested the speed, efficiency, stability of our system, including the ratio of the DNA sequences file size and original file size, the transforming speed, GC content and the number of homopolymers and Restriction Enzyme cutting sites. Additionally, we do wet lab and successfully restore our file.More details will be shown on Validation and Testing Page().
' +'2. Convince the judges you have helped any registered iGEM team from high school, a different track, another university, or another institution in a significant way by, for example, mentoring a new team, characterizing a part, debugging a construct, modeling/simulating their system or helping validate a software/hardware solution to a synbio problem..' +'
This year, we interacted with 4 other iGEM teams in a variety of activities! Our key contributions to the research of other teams were following.
' + '- ' +
'
- (1) Collaboration with the team UESTC-China, we helped them build a tool for analyzing large amount of experiment data. ' + '
- (2) Contribution to the constant of iGEM Southwest China Union (iSCU). ' + '
- (3) Organizing a meeting with TMMU and NJU.More details will be shown on Collaborations Page(). ' + '
'3. iGEM projects involve important questions beyond the lab bench, for example relating to (but not limited to) ethics, sustainability, social justice, safety, security, and intellectual property rights. Demonstrate how your team has identified, investigated, and addressed one or more of these issues in the context of your project. Your activity could center around education, public engagement, public policy issues, public perception, or other activities (see the human practices hub for more information and examples of previous teams\' exemplary work).' +'
This year, in addition to addressing DNA information storage system, we wanted to explore other issues, specifically between the scientific community and the general public. Therefore, we had done hundreds of interviews with citizens before we designed software Bio101, software Bio1024 and the game Bio2048, the three projects. We set following three questions:QUESTION 1: How much do you know about Biology? QUESTION 2: What is your attitude towards Synthetic Biology? QUESTION 3: What advantages do you want DNA storage to have?
' + 'We found universal phenomenon that many people thought that biology, especially synthetic biology is too far to touch for themselves, which became the central problem combining our project and society we aimed to solve. We tried to achieve it from three aspects that included collaborations, edutainment and DNA storage popularization.SOLUTION 1: Bio2048, popularization and feedback of edutainmentSOLUTION 2: Collaboration, the online and offline publicity and discussionSOLUTION 3: Bio101, to be scientists tomorrow. More details will be shown on Human Practice Page().
' + 'GOLD
' + '<img class="small-img" src=" " />
" />
'1. Expand on your silver medal activity by demonstrating how you have integrated the investigated issues into the design and/or execution of your project.' +'
This summer, we had done hundreds of interviews with citizens before we designed software Bio101, software Bio1024 and the game Bio2048, the three projects. Human practice, which is necessary for a birth of a project, means that every design and change should relate to humanity and make more and more practice. We addressed the above problem we found with 3 ambitious projects, which partly formed our design:
' + '(1) We created the software, Bio101, based which we held the activity, “to be scientist tomorrow”. During the activity, students in Grades 6 and 7 with their parents took part in our lecture and interactions, which promoted their interests in knowing DNA storage and other biological knowledge.
' + '(2) We created a new game called Bio2048, which encourages people to learn more about biology through an entertaining way. Not only did we put it onto the Tencent Application of Treasure for ordinary people to download and play, but also combined it with the education of biology, arousing student interests of study.
' + '(3) We contributed to the continuation of iGEM Southwest China Union as the founders of it, which highlights undergraduate research in synbio in Southwest China. As a part of that union, we organized an iGEM Meeting as well as science presentations and social activities with 4 other schools and groups.More details will be shown on Human Practice Page().
' +'2. Improve the function OR characterization of an existing iGEM project (that your team did not originally create) and display your achievement on your wiki. ' +'
During learning and consulting process, we discovered that CUHK putted forward a similar project about DNA information storage system in 2010 iGEM competition. Their system aims to store text information into DNA. We recognize their results, but there are some problems we will pose directed against their system:
' + '(1) Cannot transform arbitrary file format, only text.
' + '(2) There are too many homopolymers (i.e., repeated consecutive bases or repeated bases fragment, such as TAAAAAC or TACTTACTTACT) in the DNA sequences. This will lead to catastrophic error during the synthesizing or storing progress.
' + '(3) Not provide an appropriate error correction component in system. If a small area of DNA sequences goes wrong, its influence is deadly for the whole system.
' + 'Based on the above problems, this system is immature. In order to circumvent these defects, add more functions and own better performance, we do this:
' + '(1) Regard to a computer file, the system read its binary information first. Then, do other operation to it. In this way, the system can transform any file formats.
' + '(2) We use differential coding to ensure that there is no homopolymer in DNA sequences. We use appropriate compression coding to ensure the bases appearing in DNA sequences are almost random and guarantee lower content of G, C nucleotide
' + '(3) Our system reads of length 100 bps shifted by 25 bps so as to ensure four-fold coverage of the sequences. It means that even though one of the sequences goes wrong, it will not influence other three sequences, and we can get the information from its redundancy sequence.
' + '(4) Add a header and a footer to the sequences, which contains address code and check code. It will help identity the location of a sequence in the file and help us know whether the sequence goes wrong during the synthesizing or storing progress.More details will be shown on Project Page().
' +'3. Demonstrate a functional proof of concept of your project (biological materials may not be taken outside the lab ).You can use our software in various ways: ' +'
(1) Starting from source code — GitHub: ()
' + '(2) Install on the hard disk without having to start from source code: you can also download the install package of Bio101 in the GitHub repository, and install CORE on Windows, Mac OS X and Linux.
' + '(3) Using Bio101 online! ()Also, we have developed a detailed API document. For more details, please see documentation page(). We will demonstrate our software at iGEM Giant Jamboree in the software demo suite.
' + '4. Bring your prototype or other work to the Giant Jamboree and demonstrate it to iGEMers and judges in your track showcase (biological materials may not be taken outside the lab).We will show our project in Giant Jamboree! '
},
{
name:"Safety",
img:" ",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Bio101','Bio2048'],
content: +
",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Bio101','Bio2048'],
content: +
'Bio101
' + 'As a storage system, safety is one of the most considerable things that need us to validate. A software tool, if want to be applied in people’s life, should be proved safe in the terms of usage, consequence and practicability.
' +'Q1: What function does your software have? ' +'
A1: Bio101 is used to transform any computer file to DNA sequences, and people can use our result to synthesize DNA sequences which contain the information about the computer file. Our software also provides decoding function to rebuild your computer files from DNA sequences.
' +'Q2: Who will use your software?' +'
A2: Anyone who wants to store files for a long time and small volume will use our software.
' +'Q3: How do you verify the results that your software runs? Are they right?' +'
A3: Bio101 was ran repeatedly with different files. We did software testing from its usability and stability and document a detailed testing report. Next, we operated the whole process of Bio101. We used our software to encode a file and used the result to synthesize DNA sequences. Then stored it in specific environment. After several days, we took out the DNA and sequence it. At last, we used our software to decode the DNA sequence. As a result, and we achieved our original file.
' +'Q4: Does it have any risk in laboratory? ' +'
A4: Our software design doesn’t rely on experiments. Software itself was completed by computer and it is a web-app. In wet-lab validation, DNA sequences were synthesized, stored and sequenced by other organization. They don’t contain any functional segment and dangerous part by software testing. Therefore, it is safe and doesn’t cause any pollution.
' +'Q5: Does it have any risk in people who use your software? ' +'
A5: No, it doesn’t. We use ISAAC64—a random encryption algorithm to ensure that the bases appearing in DNA sequences are almost random. So it is scarcely possible to synthetize nucleotide sequence with specific function.
' + 'Bio2048
' + 'As for an educational game, it combines entertainment with biology knowledge, we also need to evaluate its safety for users.
'+'Q1: If your product is successful, who will receive benefits and who will be harmed?' +'
A1: The people who play the android game properly in his spare time will receive benefit. And the people who spend their all the spare time in playing the android game tend to receive harm.
' +'Q2: Where will your product be used? Can it cause pollution?' +'
A2: It is mainly used everywhere when users want to relax or learn the biology knowledge. It doesn’t cause any pollution.
' +'Q3:Does your software open source? ' +'
A3:Yes, our android game is open source.
' +'Q4: Who will use your product?' +'
A4: Everyone who are willing to play it to understand a range of important biological concepts in a more interesting way. Especially, teachers or parents may use it to make children know fundamental biology elements.
' +'Q5: Does it have some risks in health of people?' +'
A5: For Bio2048 is an Android game applied in smartphones, if people play it for a long time, their eyesight may be influenced.
' +'Q6: Does it have some risks of environment (From the wasting water or others)?' +'
A6: As a game, there is no danger to the environment.
' }
],
[
{
name:"Team",
img:" ",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Software Engineers','Art Designers','Scientists','Editors'],
",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Software Engineers','Art Designers','Scientists','Editors'],
content:'Members
' + 'Software Engineers
' + '' +
'<img src=" " /> '+
'<img src="
" /> '+
'<img src=" " /> '+
'<img src="
" /> '+
'<img src=" " /> '+
'<img src="
" /> '+
'<img src=" " /> '+
'
" /> '+
'
Engineer group owns powerful programming skills and assume the responsibility of developing software. They cooperate with each other to break away from the difficulties. Especially in the late stage of development, they must constantly correct and improve the software.
' + '' + '' + '' + '' + 'Art Designers
' + '' +
'<img src=" " /> '+
'<img src="
" /> '+
'<img src=" " /> '+
'<img src="
" /> '+
'<img src=" " /> '+
'
" /> '+
'
Art designer is responsible for the design of our wiki, poster, presentation,team sign and uniforms. They have done plenty of beautification work, which makes our work to be accepted more easily. It is their unremitting work that made our project to be presented in such an elegant way.
' + '' + '' + '' + 'Scientists
' + '' +
'<img src=" " /> '+
'<img src="
" /> '+
'<img src=" " /> '+
'<img src="
" /> '+
'<img src=" " /> '+
'<img src="
" /> '+
'<img src=" " /> '+
'<img src="
" /> '+
'<img src=" " /> '+
'
" /> '+
'
Scientist group tries to construct the state array and use FSP algorithm to simulate and predict the behavior of gene circuit. They gather and clear up those models and gene circuits ever appeared in iGEM projects, improve the method to make the prediction of genetic circuit more accurate.
' + '' + '' + '' + '' + 'Editors
' + '' +
'<img src=" " /> '+
'<img src="
" /> '+
'<img src=" " /> '+
'
" /> '+
'
The editors’ daily tasks are filing all kinds of documents. Work of Editor group is extremely trivial but important, which insights into the whole team’s progress. The final summaries of every group converge here, which we spare no efforts to amend and perfect.
' + '' + 'Mentors
' + ' " />
" />Xianlong Wang,our primary PI
 " />
" />Fengbiao Guo,our secondary PI
 " />
" />Qiong Zhang,our instructor
 " />
" />Ling Quan,our instructor
},
{
name:"Collaborations",
img:" ",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Development of Data-Processing Tool for UESTC-China','Support for TMMU_China','Meetup with TMMU_China and NJY-China','What we harvest from the collaboration'],
",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Development of Data-Processing Tool for UESTC-China','Support for TMMU_China','Meetup with TMMU_China and NJY-China','What we harvest from the collaboration'],
content:'Collaborations and sharing, the key to step forward
' + 'As iGEMers, we all know sharing and collaborations are core values of iGEM. If a team seal themselves off, not only will be trapped in projects, but also cannot stand in a higher position to grasp the overall situation. Instead of cooping ourselves up, we actively cooperate together for the betterment of synthetic biology as a whole. UESTC-Software has collaborated with other 4 teams in 3 different ways:
' + '- '+
'
- (1) Solving problems for UESTC-China, our brother team. '+ '
- (2) Mentoring and supporting TMMU-China, which is a new team. '+ '
- (3) Having meetup with SCU-China,TMMU-China,UESTC-China and SICAU. '+ '
- (4) Participating meetup with NJY-China organized by TMMU_China. '+ '
Development of Data-Processing Tool for UESTC-China
'+'Background'+'
This team’s goal is to degrade plastic and produce isobutanol. In view of increasingly serious issues on plastic pollution, greenhouse effect and energy shortage, UESTC-China comes up with an idea to try solving these three problems. That’s to use genetically modified bacteria to achieve their goal. With their work going on, there was a stumbling block related to data processing simulation.
'+ '<img src=" " />
" />
Fig.1. the experiment of UESTC-China
'Needs'+'
In the course of experiment, there was a stage where team members should complete the drawing of the enzyme activity curve, through which to compare the work effect of each plasmid vector, so as to select the best one. A sea of data made it difficult to finish the data processing by manual method. Owing to the lack of programming ability, they had to use procedural means to solve the problem which took up lots of their time and energy.
'+ 'So they seek for our support of programming. We carried forward the spirit of collaboration to solve their problems relying on our skills.
'+'Solutions'+'
In the communication process, our team members entered the lab to have an idea of what we could help. Through the analysis of the process and the dynamic combination of the varied data number, we decided to design an algorithm for the fast simulation and solve the complex work with MATLAB.
'+ '- '+
'
- 1. We batched import data collected in the experiment to MATLAB to generate a matrix, which can give the results they need quickly and accurately. Besides, it can generate EXCEL files automatically to help them do further analysis. '+ '
- 2. Another function is that the system can find out large data errors and remove these bad data. In this way, they don’t have to manually check, greatly improving the efficiency any more. '+ '
- 3. On this basis, we also provided a further function of curve fitting. With smooth curve instead of scattered data points, it makes the results more intuitive, easier to understand and analyze. '+ '
Some results are shown in Fig.2 and Fig.3:
'+ '<img src=" " />
" />
Fig.2. Enzyme activity data simulation
<img src=" " />
" />
Fig.3. Enzyme activity data analysis
The program we designed helped UESTC-China reduce the data processing time most definitely, made them come to conclusions and start next step as soon as possible.
'+ 'Support for TMMU_China
'+'Background'+'
Our team built a friendly connection with other iGEM team like TMMU, and we provided some useful supports for them in order to contribute to iGEM the competition itself, even to synthetic biology.
'+ 'During our iGEM trip, we helped TMMU_China to build Protein Calculator, a web app to predict experiment result based on their modeling.
'+ 'These programming work is time-consuming but helpful, we believe our effort can cut enormous workload and free their time so that they can focus on their experiments and research.
'+'Main work' +'
After communication and discussion about the workflow and details, our engineer group began to build and test the web app since our Chongqing Trip. We use Django to manage the web and put all necessary contents into HTML files, with related models and views in Python files.
'+ 'The main work
'+ '1. Setup the Web;
'+ '2. Fullfill all need in front end;
'+ '3. Implement file upload and download function;
'+ '4. Turn TMMU’s Matlab software into C to handle input;
'+ '5. Implement the parameter passing and result display.
'+ 'The web app
'+ 'This web app, Protein Calculator, needs three inputs: experiment parameters, cnism value and time. The first one is passed by fulfilling our standard file to upload the experiment parameters, then TMMU’s algorithm can plot a result curve to simulate the growing situation. Then, users type the specific cnism value and demand time, they can get a specific function curve at this point.
'+ 'The whole workflow is the combination of 3 modeling:
'+ '1. Gene expression model;
'+ '2. Colony growth model;
'+ '3. Protein diffuse model;
'+ 'The details of their modeling can see in <a href="https://2016.igem.org/Team:TMMU_China/Home" target="_blank">TMMU_China wiki</a>. You can also see this web app in their modeling part as a symbol of our cooperation.
'+ 'The web app
'+ 'Cooperation is always the main topic of iGEM. The interface and logrolling can really make a difference in our work progress and the friendship between different teams.
'+ 'We hope this friendship can live from iGEM2016 to a far future, and hope the web app stemming from this friendship can really help researchers to achieve their destination easily.
'+ 'iGEM Southwest China Union Meetup
'+'We are developing and growing'+'
Last year, UESTC iGEMers led the establishment of iGEM SouthWest Union of China (iSWU), which is a sustained platform for all the iGEMers in the southwest region of China. Nowadays, iSWU has a markedly increase in the number as well as the kind of teams.
'+ 'This year, there were four universities and one organization interested in synthetic biology participating in the iSWU communication held in Sichuan University. The meetup focused on the theme, “To promote the communication and cooperation among iGEM teams in the southwest region of China” and the main activity forms were to discuss teams’ projects and to share experience. It gave all teams an opportunity to achieve understanding and exchanging deeply.
'+ '<img src=" " />
" />
Fig.7. A group photo of iSWU
'We are recognized and encouraged '+'
In communication meeting, professors impressed the innovation awareness and excellent iGEM quality on us. Yun Zhao, the vice-president of SCU college oflife sciences, stressed that there is no need to mention first time in science, all science to do is the first time. Nianhui Zhang, the coach of SCU, shared the experience of his iGEM team leading trip and affirmed we were valued. His word encouraged young scholars to research on innovation and fight for great achievements.
'+ '<img src=" " />
" />
Fig.8. Our team’s presentation
'We are exchanging and improving '+'
With excellent and lively presentation, all the teams aroused passionate discussions and get numerous responses from others, including suggestions on the thoughts of project, detailed Q&A on integrated design and reflection on application. As the unique software team, we described the contents we had completed and plans to do concisely. Many members showed their interests to our project. For Bio101, some asked the DNA storage capacity and the superiority of the algorithm we used. One of the professor suggested us to take subsection coding strategy. Others played the game, Bio2048, and hoped us to help them complete the extra work such as biological game. These precious feedbacks we got from the meetup led us to what we should focused on.
'+ '<img src=" " />
" />
Fig.9. We shared with other teams
Modern technology makes information transmission more convenient, but there is no other way better than face-to-face communication. iSWU meetup helped the teams acquire reflections, inspiration and enhance efficiency to perfect the projects. Thus it can be seen, the communication will make a significant improvement for all attendees in the Giant Jamboree.
'+ 'Meetup with TMMU_China and NJY-China
'+ 'This year, TMMU-China as a young team needs a lot of support from other experienced teams. iGEM encourages helps and collaborations among teams, especially with the new teams. Just a month away from the Giant Jamboree, TMMU-China invited UESTC-Software, UESTC-China and NJY-China to gather in Chongqing. They arranged a meetup and aimed to prepare for the final presentation in Boston.
'+ '<img src=" " />
" />
Fig.10. The group photo in TMMU-China
'The same experience, the same mood'+'
As an excellent team, we are full of enthusiasm to share our rich experience of competition and provide guidance for them. TMMU-China is in unclear condition for iGEM as we once were. We can deeply feel the mood of them. Therefore, we hoped to collaborate with them to give them courage.
'+ '<img src=" " />
" />
Fig.11. The presentation of TMMU-China
'The different styles, the different feels'+'
This meetup was completely consistent to the final competition process, with 15-20 minutes for presentation, question time and poster introduction. Although the scale was not better than the final event, it was really a good opportunity to feel different styles of presentation. We exchanged the final preparation for the competition, discussed the summary of the achievement, and found the problems existing in many aspects.
'+ '<img src=" " />
" />
Fig.12. We communicated with the teachers from TMMU-China and NJY-China
'The new collaboration, the new harvest'+'
Significantly, it was our first time to contact with NJY-China. We learned from their indefatigable efforts. They were willing to cooperate with other teams and visit different universities to make improvement. They focused on public awareness about the spread of synthetic biology knowledge. Our Human Practice is doing the same effort.
'+ '<img src=" " />
" />
Fig.13. The introduction from NJY-China
The meetup was hold on the basis of project’s completion, so we inspired each other in all aspects. With such a good platform for collaboration, we can help others and recognize ourselves at the same time, become less blind and less helpless. We got the inspiration from sharing, we found the courage from communicating.
'+ 'What we harvest from the collaboration
'+ 'Through all the collaborations we took part in, we learned a lot and shared happiness. We knew collaboration, competition and communication deeper and better. What we acquired is not only about the iGEM competition itself, we made friends and expanded our eyesight. We communicated face to face to understand what they did and make them know what we were doing , through which we improved our own abilities. And we encouraged and competed each other to hold on the scientific trip, which made us know about the importance of the competitors and collaborators to scientific workers. All these memories will be a unique part of the iGEM experience as well as our scientific life experience.
'+
},
{
name:"Notebooks",
img:" ",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
type:"PDF",
src:['https://static.igem.org/mediawiki/2016/e/e6/Uestc_software-E_Week_1--Caixi_Xi.pdf','E Week 1--Chenxiang Zhen.pdf','E Week 1--Dongkai Pu.pdf','E Week 1--Hao Xu.pdf','E Week 1--Haobo zhou.pdf','E Week 1--Hui Che.pdf',
'E Week 1--Jianwei Xu.pdf','E Week 1--Jun Li.pdf','E Week 1--Mingfei Ding.pdf','E Week 1--Wei Zhao.pdf','E Week 1--Xin Ma.pdf','E Week 1--Yuening Yan.pdf',
'E Week 1--Zhongtian Ma.pdf','E Week 1--Zining Wu.pdf','E Week 2--Meng Liu.pdf','Notebook-Report.pdf'],
catalogue:['Caixi Xi','Chenxiang Zhen','Dongkai Pu','Hao Xu','Haobo zhou','Hui Che','Jianwei Xu','Jun Li','Mingfei Ding','Wei Zhao',
'Xin Ma','Yuening Yan','Zhongtian Ma','Zining Wu','Meng Liu','Notebook-Report']
}
],
[
{
name:"DOCUMENT",
img:"
",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
type:"PDF",
src:['https://static.igem.org/mediawiki/2016/e/e6/Uestc_software-E_Week_1--Caixi_Xi.pdf','E Week 1--Chenxiang Zhen.pdf','E Week 1--Dongkai Pu.pdf','E Week 1--Hao Xu.pdf','E Week 1--Haobo zhou.pdf','E Week 1--Hui Che.pdf',
'E Week 1--Jianwei Xu.pdf','E Week 1--Jun Li.pdf','E Week 1--Mingfei Ding.pdf','E Week 1--Wei Zhao.pdf','E Week 1--Xin Ma.pdf','E Week 1--Yuening Yan.pdf',
'E Week 1--Zhongtian Ma.pdf','E Week 1--Zining Wu.pdf','E Week 2--Meng Liu.pdf','Notebook-Report.pdf'],
catalogue:['Caixi Xi','Chenxiang Zhen','Dongkai Pu','Hao Xu','Haobo zhou','Hui Che','Jianwei Xu','Jun Li','Mingfei Ding','Wei Zhao',
'Xin Ma','Yuening Yan','Zhongtian Ma','Zining Wu','Meng Liu','Notebook-Report']
}
],
[
{
name:"DOCUMENT",
img:" ",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
type:"PDF",
src:['https://static.igem.org/mediawiki/2016/4/4a/Uestc_software-Bio101_Development_GuideV2.pdf','Bio101 User GuideV2.0.pdf','Bio2048 Development GuideV2.0.pdf','Bio2048 Users GuideV2.0.pdf'],
catalogue:['Bio101 Development Guide','Bio101 User Guide','Bio2048 Development Guide','Bio2048 Users Guide']
}
],
[
{
name:"HUMAN PRACTICES",
img:"
",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
type:"PDF",
src:['https://static.igem.org/mediawiki/2016/4/4a/Uestc_software-Bio101_Development_GuideV2.pdf','Bio101 User GuideV2.0.pdf','Bio2048 Development GuideV2.0.pdf','Bio2048 Users GuideV2.0.pdf'],
catalogue:['Bio101 Development Guide','Bio101 User Guide','Bio2048 Development Guide','Bio2048 Users Guide']
}
],
[
{
name:"HUMAN PRACTICES",
img:" ",
mediaSrc:"https://static.igem.org/mediawiki/2016/6/67/Uestc_software-game.mp4",
catalogue:['Our Approach','Evaluation of Our Approach','Impact on Our Scientific Project','Benefits shared out','Special practice: the show on University’s 60th Anniversary'],
content:+
",
mediaSrc:"https://static.igem.org/mediawiki/2016/6/67/Uestc_software-game.mp4",
catalogue:['Our Approach','Evaluation of Our Approach','Impact on Our Scientific Project','Benefits shared out','Special practice: the show on University’s 60th Anniversary'],
content:+
'With More Humanities, Do More Practices.
' + '<a href="https://www.youtube.com/watch?v=p5TcoXEG3v8" target="_blank"><img src=" " /></a>
" /></a>
In order to understand the extent of the public’s understanding of biology and synthetic biology for planning our Human Practices, we interviewed hundreds of citizens before our projects started. We hope that we can learn the current social situation and get the project inspiration. From the investigation, the problems existing will make our Human Practices significant and targeted. The feedback we received for using will push our project closer to the public.
'+ 'During the interviews, we asked 3 different questions:
'+ 'Question1: How much do you know about Biology?
'+ 'Question2: What is your attitude towards Synthetic Biology?
'+ 'Question3: What advantages do you want DNA storage to have?
'+ 'There is no doubt that we will get lots of different feedback. We aimed at getting in touch with more and more people, understanding what they are interested in, making clear what they misunderstand. The results of investigation are showed below.
'+ '<img src=" " />
" />
Fig.1.The degree of understanding pie chart.
In order to know the situation in different age groups, we conducted a more detailed statistical analysis of the survey results. This helped us to take different approaches to people of different ages.
'+ '<img src=" " />
" />
Fig.2.The degree of different ages understanding bar chart.
We can see, the situation is serious. It’s very important and necessary to change it. In this summer, we tried our best to spread the knowledge about Biology and influence more people. As iGEM spirit encouraged us, we are willing to drive more people to learn biology.
'+ 'Our Approach
'+ 'During the interview and investigation, we found that many misunderstandings existed in the society nowadays. Even though the problem is universal while our strength is thin, we tried to solve it from little things we can do. Sometimes, little things have large effect.
'+'STEP 01, Propaganda'+'
"Science for all" is a central concept in contemporary science education.
'+ 'We decided to talk to the public about the knowledge of synthetic biology to understand their views and attitudes towards synthetic biology. There is a wide range of people in community, including people from different industries and people of all ages. So community is a certain representative place to do propaganda. In the meantime, we took forms of posters publicity and leaflets distribution to exert more profound and durable influence on the masses; we interviewed passersby to directly learn about the level of people’s understanding of synthetic biology and change their wrong views. In order to increase the scope of publicity and improve the credibility of the results of the interviews, our footsteps are around every corner in Chengdu. As the communities we interviewed are shown in the picture following.
'+ '<img src=" " />
" />
Fig.3.The places we interviewed.
In addition to conducting interviews and introductions, we had to do focused and targeted propaganda. As we believed that students in primary and middle school are the most people in need to receive some basic education about biology and synthetic biology we paid attention to holding the lecture and activity to arouse their interest in science. In the lecture, we showed synthetic biology and iGEM with stories and videos to more than 200 students in Puyang Junior High School. We built plasmids with functions we wanted together.
'+ 'As we all know, putting theory into practice is very important. Students in Grades 6 and 7 accompanied by their parents took part in our activity, “To Be Scientist Tomorrow”. We led them to do a little experiment that extracting DNA from banana, but all equipment was used in our daily life (such as dishwashing, storage bags, etc.). All of the kids successfully accomplished the lab driven by interest.
'+ '<img src=" " /></br>Fig.4.The students are making experiments by themselves.
" /></br>Fig.4.The students are making experiments by themselves.
'STEP 02, Edutainment'+'
For many people, biology is a subject that they are unfamiliar with. In society, People lack the mediums to contact with biology. Biology is separate from ordinary people’s life. We decided to adopt a more acceptable way to make more people touch it directly. So, we combined the conceptions of biology with the well-known game-2048.
'+ '<img src=" " /></br>Fig.5.The attitude of people to learn biology.
" /></br>Fig.5.The attitude of people to learn biology.
We created a new mobile phone game called Bio2048, which encouraged people to learn more about biology in an entertaining way. Not only did we put it onto the Tencent Application of Treasure for ordinary people to download and play, but also pushed its information in our sina microblog and Qzone to collect feedback. Combining it with the education of biology, we aroused students’ interests of study.
'+ '<img src=" "/></br>Fig.6.The interface of Bio2048.
"/></br>Fig.6.The interface of Bio2048.
In order to learn the effect of Bio2048 for improvement and propaganda, we organized a “game-try” activity in the street. Almost 200 people tried our game, and an overseas student impressed us much. He expressed much interest in our game, and got really high score. When we asked him, he said he had touched similar game before, and he made a positive comment on the edutainment form, which made us know that our process is beneficial.
'+ '<img src=" "/></br>Fig.7.The foreign friend is playing Bio2048.
"/></br>Fig.7.The foreign friend is playing Bio2048.
With everybody’s suggestion and the high praise, we hoped our achievement would be taken into class, because the biology knowledge in game agreed with the contents in book and the students preferred the original class tools. We introduced our outcome to students and teachers who were glad to help us access application in class. Puyang lecture was the first time to take Bio2048 to class. Students had high enthusiasm to play our games. After that, we contacted with educational services to try the game in class.
'+ '<img src=" "/></br>Fig.8.Bio2048 in class.
"/></br>Fig.8.Bio2048 in class.
'STEP 03, Inspiration'+'
During the period that we learned and thought about our project, we considered to take some actions to seek inspiration. We hold a lecture with UESTC-China in Puyang Junior High School. We introduced synthetic biology with some well-known examples at first. Then, it was time for the students to build their own plasmids. They added the functional genes like Bioluminescence gene into the plasmids. So the plasmids carried the information of the light emitting gene. “The plasmid carried the information of biological characteristics” inspired us: was DNA able to carry a wide variety of information? Along this idea, we explored the DNA information storage.
'+ '<img src=" "/></br>Fig.9.We are building the plasmids together.
"/></br>Fig.9.We are building the plasmids together.
When we were designing our software, we hoped the idea would come from the public. After all, the final software achievement will return to life. We did street interviews, from campus to market. We wanted to hear the voice of the public’s imagination to the DNA information storage system. In surprise, we received many useful information from the communication. A young man’s opinion left the deepest impression on us: he nearly had higher expectation for the storage capacity, equipment volume and storage speed. He had special interest in our project and gave us great help to decide the property and function of software.
'+ '<img src=" "/></br>Fig.10.The interview about Bio101.
"/></br>Fig.10.The interview about Bio101.
Sometimes, we would be restricted in the knowledge we already have. In terms of creativity, we are far from children. To have a future blueprint of our project, we talked with pupils about the DNA information storage in the activity, “To Be Scientists Tomorrow”. They were very active and said they wanted the files would not be lost. Children said what they like, absolutely, their innocence inspired us.
'+ '<img src=" "/></br>Fig.11.A girl is imaginating about Bio101.
"/></br>Fig.11.A girl is imaginating about Bio101.
We collected the professors’ suggestions besides the ordinary people. We met and discussed in iGEM Southwest China Union. The participants not only focused on software functions, but also were curious about the algorithms. During the communication, they gave suggestions about the development of software performance from a professional view.
'+ 'Evaluation of Our Approach
'+ 'On the way to achieve our goal, we concentrated on the progress of our project and its result. As we found there were the points that were not considered, we decided to change our approach. Throughout this process, we learned evaluation is a result of hard work.
'+'Evaluation of Propaganda' +'
According to various interviews, in fact, most people generally believed something related to synthetic biology is dangerous. So they did not eat genetically modified food as far as possible. We introduced simply about synthetic biology and tried to eliminate their mistakes. Obviously, not all of people can accept us. But we will continue to make efforts to correct the thinking of public.
'+ 'From the lecture, students knew more about synthetic biology and are all more interested in biology. Creating plasmids by their own hands makes the technology easily understood. Then the activity let children feel biology more directly through doing experiment by themselves. We remember one boy said that experiment is untouchable in ordinary life, today he felt cool and excited. This is what we want to achieve. The activity changed the stereotyped images of biology, and it becomes vivid in masses’ eyes. Young children are new-rising force of our country. Letting them realize the great development prospect and arousing their interests in biology are significant to continue biology studies.
'+'Evaluation of Edutainment'+'
Bio2048 is a special tool to learn biology. We practiced to test its feasibility. We opened a sina microblog to push our project progress and it has already attracted 1030 fans. Many people made comments after trying, and most said that the game was attractive for the combination of knowledge and enjoyment. Some thought that our game was lack of description words, therefore, we added introductions to build a learning mode in the game for easier understanding.
'+ 'Students in primary and middle school are extremely interested in the way of acquiring new conceptions. Teachers are surprised to see that it isn’t only a kind of edutainment but also an integration of math and biology. In the activity, “To Be Scientists Tomorrow”, we held a Bio2048 game. A parent, as a biology teacher, was delighted in Bio2048, and she thought it was very educational and necessary to be introduced and used in class. Surely, it was a recognition of our work and we are trying our best to realize the idea. We are willing to develop more tools like Bio2048, combining education with interest and focusing on the contents and forms. We believe, our work will influence more people to learn and research biology.
'+'Evaluation of Inspiration ' +'
We do Human Practices to practice our thoughts and get inspirations. However, we are surprised to find the effect is bidirectional.
' + 'In Puyang lecture, we got the inspiration of our project. At the same time, the operation of building plasmids was an opportunity for the students to stimulate their creativity and imagination. We interviewed the public, it was a way to contact them with science. Some products appear to solve the inconvenience of life. So, everyone should dare to imagine. As to students, their rich imagination was an eye-opener to us. Introducing our ideas to pupils will deepen their understanding of biology and show the great prospects for the development of Biology. These practices arouse people’s interests in biology and make them improve their initiative, especially to the students, who undertake the mission of continuing to move forward.
' + 'We can see that our Human Practices are mutually beneficial and win-win.
'+ 'Impact on Our Scientific Project
' + '<img src=" " /></br>Fig.12.Our presentation in iSWU.
" /></br>Fig.12.Our presentation in iSWU.
Human practice, which is necessary for the birth of a project, means that every design and change should be related to humanity and make more and more practice. Therefore, the impact on our project will be the center we consider and summarize.
' + 'When we first tried to make our inspiration come true, we interviewed and asked people for advice, and our instructor, classmates, friends in iGEM Southwest China Union gave us lots of suggestions, which were about icon design, conception definition, user interface, compression algorithm and so on. As the video you can see, the three questions are the origin of our inspiration, which provides continuous ideas and creations for us.
' + 'During the interview and invitation, we completed designs, then some interviewers in different occupations including primary school and middle school students, passers-by and teachers, provided their feedback to us, most of which was the feeling of this game and some of them helped us improve our methods.
' + '' + '
As we put great effort in the design of our project, we want to share what we can do within and beyond iGEM. No one is an island, hence, we believe that we can change a little around ourselves, which can influence more and more people. Different people have different understanding about science, about biology, what we do can make the basic knowledge closer to ordinary people and help them build a valid view of science.
' +'For students' +'
As we believed students in primary and middle school are the most people in need to receive some basic education about biology and synthetic biology to promote their interests. We did a series of activities to achieve this. The students showed great interest to our educational games, during which they hand-on practiced and smiled after they had completed the tasks. We found their enthusiasm grown after the game and they asked us more questions which becomes more imaginative than before. We could feel their happiness when we said goodbye. We believe that the smile is the seed of science rooted in their heart, which we wish can thrive along with them.
' +'For teachers' +'
Nowadays, many Chinese teachers are bothered by how to make knowledge easier to understand and how to push themselves closer to students. Maybe what we did cannot solve problems essentially, however, we trust that the edutainment is one of the most efficient ways to do something better. The way we convey the knowledge to students, such as the game Bio2048 and plasmid model created by hand, can give an inspiration to teachers.
' +'For ordinary people' +'
Ordinary people are liable to misunderstand biology in our investigation. After our propaganda and popularization of biology science, more than 71% people changed their misunderstanding to biology technology. They acknowledged they did not realize that biology and technology was used so widely in everyday life. Otherwise, more than 84% people held a friendly attitude towards tomorrow’s biology development. An old gentleman expressed giant interest about our project Bio101 after our propaganda and was willing to drop in our lab, which surprised us a lot.
' + '<img src=" "/></br>Fig.13.The public’s attitude changed after our effort.
"/></br>Fig.13.The public’s attitude changed after our effort.
Special practice: the show on University’s 60th Anniversary
'+ 'On September 29th, 2016, here comes the 60th birthday of our university. With our project completed, we grasped the anniversary chance to show our achievement.
'+ '<img src=" "/></br>Fig.14.We are introducing our project to the foreign visitors.
"/></br>Fig.14.We are introducing our project to the foreign visitors.
Schoolfellows took care of the situation of scientific research and were willing to learn the creative works from students. We set an introduction station to demonstrate what we did this summer. We also took Bio101 in this display to let visitors have a try. Most visitors were professional, so our topic of communication was well over our project. We discussed the synthetic biology development trend, we compared electronic computer with biological computer. Schoolfellows said that not only our project but also DNA information storage system could represent a brand new field, which had huge potential and wide prospect.
'+ '<img src=" "/></br>Fig.15.A visitor is trying our software.
"/></br>Fig.15.A visitor is trying our software.
In the 60-year-old celebration, we showed iGEM, our achievement and the burgeoning subject of nowadays technology. Facing the smile and affirmation of school fellows, we felt what we did was so meaningful. At the same time, we hope our partners in UESTC can be on the way for the palace of scientific research all along.
'+
}
],
[
{
name:"ATTRIBUTIONS",
img:" ",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Member Attribution','Special Thanks to'],
content: +
",
mediaSrc:"https://2016.igem.org/Team:UESTC-software",
catalogue:['Member Attribution','Special Thanks to'],
content: +
'This summer a team composed of fifteen members from UESTC, also from different hometowns, took part in the iGEM international competition. We gathered together to explore biological storage, to seek more accurate algorithms for simulating gene circuits, to optimize user interface more and more, again and again. During the process, every one made an effort, beyond this. We also received a lot of help from other people, which encouraged us to create our best work.
'+ 'Member Attribution
'+ 'Project'+
'DNA storage design'+
'Front-Web: Jianwei Xu, Jun Li, Meng Liu
'+ 'Encode and Decode Algorithm: Dongkai Pu, Meng Liu
'+ 'Backstage and Webpage Construction: Dongkai Pu, Jianwei Xu
'+ 'Documentation: Meng Liu, Jun Li
' +'Bio2048 design'+'
User Interface: Xin Ma
'+ 'Programming: Xin Ma
'+ 'Icon Degisn:Haobo Zhou
'+ 'Hierarchical Conception: Zhongtian Ma
' +'Bio1024 design'+'
Modeling: Chenxiang Zheng, Hao Xu
'+ 'Array construction: Hao Xu, Chenxiang Zheng, Wei Zhao
'+ 'Coding and experiment: Zhongtian Ma, Jianwei Xu
'+ 'Documentation: Yuening Yan, Caixi Xi
'+ 'Front-Web: Mingfei Ding
'+ 'Image Design and Edition: Xin Ma, Zining Wu
' + 'Human Practice and Collaboration'+
'Collaboration with Southwest Alliance'+
'Presentation: Chenxiang Zheng
'+ 'Poster: Zining Wu
'+ 'Brief Introduction: Hui Che
' +'Collaboration with UESTC-China'+'
Prgramming and Documentation: Jianwei Xu
' +'Collaboration with TMMU'+'
Uncertain
' +'Science Lecture'+'
Material Prepare: Caixi Xi, Hao Xu
'+ 'Presentation: Yuening Yan, Hui Che
'+ 'PPT Design:
'+ 'Photo: Haobo Zhou
'+ 'Documentation: Yuening Yan, Hui Che
' +'“To Be Scientists Tomorrow”visiting activity'+'
Design and Plan: Hao Xu
' +'Team’s Weibo public platform'+'
Management: Zhongtian Ma
' +'Community advocacy'+'
Design and Plan: Caixi Xi
' + 'Art and Design'+
'Wiki'+
'Programming: Mingfei Ding, Meng Liu
'+ 'Design: Haobo Zhou
'+ 'Copywriting: Hui Che, Yuening Yan, Meng Liu, Caixi Xi, Wei Zhao, Zhongtian Ma
'+ 'Chenxiang Zheng
' +'Team sign and Uniforms'+'
Inspiration: Haobo Zhou
'+ 'Design and Draw: Zining Wu, Xin Ma
' +'Plan for Boston'+'
Uncertain
'+ 'Special Thanks to
'+'Professor Xianlong Wang, our primary PI'+'
For helping the UESTC Software team design and plan our project. His guidance to all 15 members is greatly appreciated.
'+'Ling Quan,our instructor'+'
For her leadership and teaching us how to build a team. She taught us how to become more friendly and united. Also, she gave us advice on travel to Boston and the contents of our presentation.
'+'Kaiyue Zhang, the team leader of 2015 UESTC-China, and Yaocong Duan, the team leader of 2015 UESTC-Software.'+'
For giving us advice on building our team and disciplines, providing support to us outside of training, which encouraged us to perfect our project.
'+'Xu Wang, system administrator in Xingchen studio'+'
For building the server and helping us set up backstage when we had problem during visualization design.
'+'Bohan Li, Ziyun Guan, Jingyi Wang, Huanghao Yang, Wei Liu, the Preliminary Team Members (sophomores of UESTC).'+'
For helping us with human practice including the implementation of the visiting activity “To Be Scientists Tomorrow” and Community Advocacy. Their help is especially appreciated for taking photos, shooting videos and preparing materials.
'+ 'Other teams taking part in the competition'+
'
'+
'<a href="https://2016.igem.org/Team:SCU-China" style="color:#3C9CD3;text-indent:28px;font-size:15px;" target="_blank">       Sichuan University</a>'+
'
'+
'<a href="https://2016.igem.org/Team:Nanjing-China" style="color:#3C9CD3;text-indent:28px;font-size:15px;" target="_blank">       Nanjing University</a>'+
'
'+
'<a href="https://2016.igem.org/Team:TMMU_China" style="color:#3C9CD3;text-indent:28px;font-size:15px;" target="_blank">       Third Military Medical University</a>'+
'
'+
'<a href="http://www.sicau.com" style="color:#3C9CD3;text-indent:28px;font-size:15px;" target="_blank">       Sichuan Agricultural University</a>'+
'
'+
'<a href="https://2016.igem.org/Team:UESTC-China" style="color:#3C9CD3;text-indent:28px;font-size:15px;" target="_blank">       Experiment team from UESTC</a>'+
'For discussing our projects with us and putting forward some views and suggestions to improve our task.
'+'The Developers of Following Libraries'+'
wout/svg.js(link:\'https://github.com/wout/svg.js\'):A lightweight library for manipulating and animating SVGjquery/jquery(link:\'https://github.com/jquery/jquery\'):jQuery JavaScript LibraryFor the former making our work in generating SVG images more convenient, and help us encapsulate DOM and AJAX operation, as well as simplify grammar.
'+'Dean’s Office of University of Electronic Technology and Science of China'+'
It’s a great deal for us that the dean’s office provided our funds during the competition. The Dean’s Office covered the flight fees, accommodation and also Team Registration Fees and the Jamboree Attendance Fee, which greatly reduced our financial burden and motivated us to focus on the competition.
'+ 'Thanks again to all people involved for helping us be a more successful iGEM team. This summer, because of your support, we can better ourselves.'+
'
'+
'
'+
'<img src=" " style="width:70%;margin-left:140px;"></img>'+
}
]
" style="width:70%;margin-left:140px;"></img>'+
}
]
];
var id = 0;
var index = 0;
var currentUrl = location.href.toString();
if(currentUrl.indexOf("?id=") >= 0){
id = parseInt(currentUrl.split("?id=")[1]);
} if(currentUrl.indexOf("&index=") >= 0){
index = parseInt(currentUrl.split("&index=")[1]);
} showContent(id,index); function showContent(id,index){
if(data[id][index].type == "PDF"){
var str = '<embed class="load-pdf" width="100%" height="100%" src="../libs/'+data[id][index].src[0]+'"></embed>';
var htmlStr = ;
for(var i = 0; i < data[id][index].catalogue.length; i++){
htmlStr += ' }
var codeStr = '<img src="'+data[id][index].img+'" class="title-img" />
'+
''+data[id][index].name+'
'; $(".content-top").html(codeStr);
$(".catalog-area ul").html(htmlStr);
$(".detail-content").append(str);
$('.catalog-area ul li a').click(function(){
$(".load-pdf").attr("src",$(this).attr("name"));
});
return;
}
var htmlStr = ;
if(data[id][index].catalogue.length == 0){
$(".catalog").addClass("active");
}
for(var i = 0; i < data[id][index].catalogue.length; i++){
htmlStr += '} var str = '<img src="'+data[id][index].img+'" class="title-img" />'
'+
'+data[id][index].name+'
'; if(data[id][index].mediaSrc){
$(".detail-content").html(data[id][index].content);
}
$(".catalog-area ul").html(htmlStr);
$(".content-top").html(str);
$(".img-head-p > img").mouseenter(function(){
var subArr = [0,4,7,12,14];
var parentIndex = $(".img-head-p").index($(this).parent());
var index = parseInt($(".img-head-p > img").index(this)) + 1 - subArr[parentIndex];
$(".text-div").eq(parentIndex).find(".text-p").eq(index).css("display","block").siblings().css("display","none");
});
$(".img-head-p").mouseleave(function(){
var parentIndex = $(".img-head-p").index(this);
$(".text-div").eq(parentIndex).find(".text-p").eq(0).css("display","block").siblings().css("display","none");
});
}
$(".scroll-top img").addClass("active"); $(".catalog").click(function(){
$(this).addClass("active");
$(".catalog-area").addClass("active");
}); $(".catalog-area .title").click(function(){
$(".catalog-area").removeClass("active");
$(".catalog").removeClass("active");
}); $(".scroll-top img").click(function(){
$('html, body').animate({scrollTop:0}, 'slow');
}); $(window).scroll(function(){
var height = $(document).scrollTop();
if(height > 300){
$(".scroll-top img").removeClass("active");
}else{
$(".scroll-top img").addClass("active");
}
});