Difference between revisions of "Team:Edinburgh UG/Software"
F1yingFish (Talk | contribs) |
F1yingFish (Talk | contribs) |
||
| Line 100: | Line 100: | ||
<div class="row full-size"> | <div class="row full-size"> | ||
<div class="col-sm-1"></div> | <div class="col-sm-1"></div> | ||
| − | <div class="col-sm- | + | <div class="col-sm-10"> |
<img class="img-responsive img-center" src="https://static.igem.org/mediawiki/2016/8/8c/EdiGEM16UGsoftware1.jpeg" alt=""> | <img class="img-responsive img-center" src="https://static.igem.org/mediawiki/2016/8/8c/EdiGEM16UGsoftware1.jpeg" alt=""> | ||
</div> | </div> | ||
| + | <div class="col-sm-1"></div> | ||
</div> | </div> | ||
</header> | </header> | ||
Revision as of 10:05, 15 October 2016

A checksum is a commonly used technique in network engineering that we’ve adapted for use in DNA storage. In this format the checksum allows the detection of errors in a BabbleBlock (DNA sentence). The checksum holds the sum of the word coding regions of BabbleBricks (DNA words) in a BabbleBlock in a 4 BabbleBrick region that can be found towards the end of a BabbleBlock.
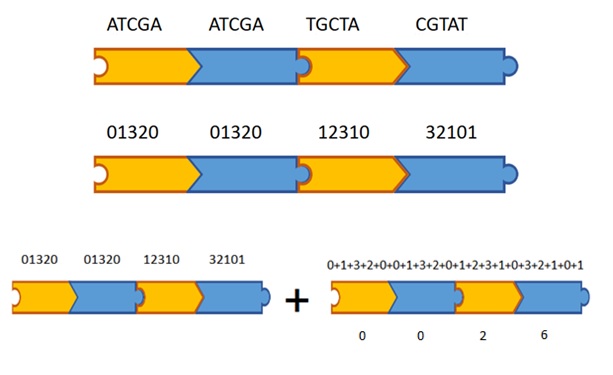
When a BabbleBlock is being translated the checksum is looked at first to see if it matches the sums of the word coding regions in the DNA we get back from sequencing. If this is the case, no errors have appeared and the translation program can proceed as normal however if there is no match an error has occurred somewhere in the BabbleBlock and other error correcting mechanisms will have to be used to make sure the stored information can still be read back.
The Optimal Rectangular Code (ORC) is a type of error correcting code that is present in all of our BabbleBricks. When the checksum detects an error the next action is to checks the ORCs in each word and use them to correct any errors that have taken place as follows:

Unfortunately, the ORC can only locate and fix single base pair errors however the properties of the ORC facilitate another added level of error correction.
If the Optimal Rectangular Code (ORC) detects more than the single base pair error it can fix using its normal actions the SuperFixer function is called. The SuperFixer uses the ORC and works out all the possible words in the lexicon that fit this pattern. For any given ORC this is a maximum of 4 words and indeed there are many words that have unique ORC’s. Once the SuperFixer has narrowed down the possible words the list of possibilities is compared to what appears in the actual DNA and the sequence with the lowest Levenshtein distance is used in the translation. Levenshtein distance is a metric which shows the number of deletions, insertions or substitutions it will take to turn one string (or sequence) into another.

By taking the minimum Levenshtein distance we always work under the assumption that the smallest number of errors is most probable. This assumption gives the best performance across errors of different magnitudes due to the robustness of DNA as a molecule making small errors considerably more likely than larger ones.


