To create BabblED, we needed to rapidly design and process the information in a lexicon of over 2000 BabbleBricks. This would have been a practically impossible task without a novel computational approach. In order to make BabblED accessible our software needed to be open source (our code can be found on githubor on our dedicated wiki page), have an easy to use and elegant user interface, and run under reasonable time constraints (it's possible to encode entire lexicons practically instantly). In addition to the easy and fast encoding and decoding of our BabbleBricks we needed to automate our unique DNA error correction system; adapting a number of computer science techniques to new and creative applications in DNA storage. Finally, with data security an ever growing concern we implemented a highly secure DNA encryption system to safeguard against unauthorised access.
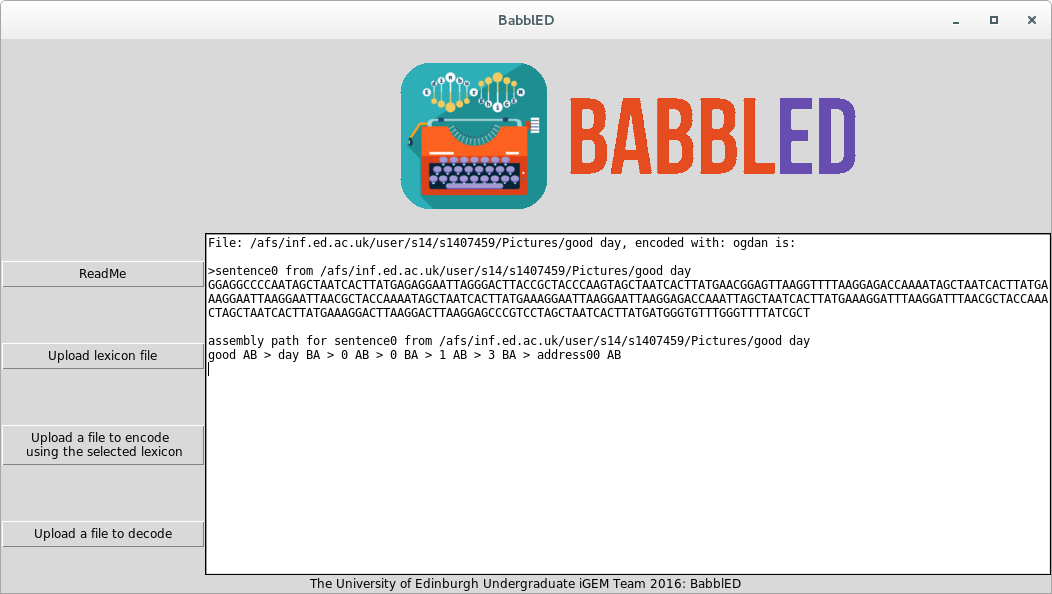
When the user starts up the BabblED software they are presented with the following screen and options.
Lets assume that this is the users first time with the BabblED software. A natural first move would be to select the ReadMe option from the menu. This will display a piece of text with brief explanations of the informatics concepts behind BabblED.
After reading through the user decides they would like to look at a lexicon. Now there are two options the user can use the ogdan's basic english (ogdan's basic english being a collection of the most expressive words in english) lexicon that comes with the BabblED distributable.
Alternatively they can create their own lexicon. This simply requires having each individual piece of information they wish to encode on a separate line in a text file ready to be loaded into the program.
After encoding a lexicon the next important functionality is to encode some piece of data. For this example we'll use some words from ogdans basic english for example good day. The user simply enters their information into a text file, like so:
This is then loaded into the program giving the sequence of the resulting BabbleBlock and the BabbleBricks required to encode it:
Some time later we now need to retrieve this information. After getting the BabbleBlock from sequencing we load it into the program.
Recieving back the encoded information with any necessary error correction already having been performed.
Design Considerations:
Why Python?
Python is high-level, general purpose language designed for quick creation of highly readable code. As a result of libraries such as BioPython it has becoming increasingly used in Bioinformatics and Computational Biology in recent years this made it the obvious choice for the BabblED software. We made the decision to use Python 2.7 to increase accessibility as this is the Python version commonly pre-installed on Linux distributions such as Ubuntu.
Why avoid a web app?
When developing our software we carefully considered how it should be deployed. Should we create a web app using Django (the commonly used Python web framework)? Or simply make all our code easily downloadable with documentation on how to run it? Despite the minor drawbacks in accessibility we eventually settled on the later option for two main reasons. Firstly BabblED was designed for encoding large amounts of archival data - such large amounts that sending these volumes over the web would be very impracticable. Secondly having put a lot of work into the data security angle of the project we deemed that the web app approach had a much higher chance to introduce unforeseen security flaws that we knew (not being computer security experts) we would not have the capabilities to protect against.