Difference between revisions of "Team:Edinburgh UG/Lexicon Encoding"
F1yingFish (Talk | contribs) |
F1yingFish (Talk | contribs) |
||
| Line 130: | Line 130: | ||
<div id="collapseOne" class="panel-collapse collapse"> | <div id="collapseOne" class="panel-collapse collapse"> | ||
<div class="panel-body"> | <div class="panel-body"> | ||
| − | <p> | + | <p>To encode the BabbleBricks that make up a lexicon we begin by taking a list of words. We then enumerate this list first in decimal and then in base 4. We convert these numbers into their DNA equivalent using the schema; A is 0, T is 1, G is 2, C is 3 and pad them all up to 5 base pairs. Now we have these variable sequences we must ensure that no illegal |
| + | restriction sites can occur so we add gap sequences. Finally we append a stop codon region, restriction site preventing gapped error correcting region and hangs in each BabbleBrick form. For example:</p> | ||
<img src="https://static.igem.org/mediawiki/2016/d/d1/EdiGEM16ug_checksum.jpeg" class="img-responsive center-block"> | <img src="https://static.igem.org/mediawiki/2016/d/d1/EdiGEM16ug_checksum.jpeg" class="img-responsive center-block"> | ||
| − | |||
</div> | </div> | ||
</div> | </div> | ||
| Line 144: | Line 144: | ||
<div id="collapseTwo" class="panel-collapse collapse"> | <div id="collapseTwo" class="panel-collapse collapse"> | ||
<div class="panel-body"> | <div class="panel-body"> | ||
| − | <p> | + | <p>When we assemble our BabbleBricks together to create BabbleBlocks its vital we know what the sequence will be for both verification purposes, so that we can instruct the user exactly which BabbleBricks to use and so we can work out our checksum and address values. We start by appending our word coding BabbleBricks together:</p> |
<img src="https://static.igem.org/mediawiki/2016/2/2a/EdiGEM16ug_orc.jpeg" class="img-responsive center-block"> | <img src="https://static.igem.org/mediawiki/2016/2/2a/EdiGEM16ug_orc.jpeg" class="img-responsive center-block"> | ||
| − | <p> | + | <p>We then look at the word coding regions spaced at regular and use them to calculate a checksum as described in the checksum section below. Finally, we append an address BabbleBlock which acts like a line number telling the decoding program where this BabbleBlock lies in the overall archive.</p> |
</div> | </div> | ||
</div> | </div> | ||
| Line 158: | Line 158: | ||
<div id="collapseThree" class="panel-collapse collapse"> | <div id="collapseThree" class="panel-collapse collapse"> | ||
<div class="panel-body"> | <div class="panel-body"> | ||
| − | <p> | + | <p>In order to decode a BabbleBlock we first look at our checksum and use it to verify whether or not error correction needs to be done - if some mistakes are flagged we use our error correcting apparatus, as described below, and return their results (what our sequence was before the change) back to the decoding program. The error correcting program will look at each word coding region, convert it back to it numerical values and use it as an index to look up the information value of that BabbleBrick in the lexicon. Having decoded all the BabbleBlocks in a batch these will then be sorted in order using the address found at the end of each sequence before the decoded information is returned to the user.</p> |
| − | + | ||
| − | + | ||
</div> | </div> | ||
</div> | </div> | ||
Revision as of 11:28, 15 October 2016

To encode the BabbleBricks that make up a lexicon we begin by taking a list of words. We then enumerate this list first in decimal and then in base 4. We convert these numbers into their DNA equivalent using the schema; A is 0, T is 1, G is 2, C is 3 and pad them all up to 5 base pairs. Now we have these variable sequences we must ensure that no illegal restriction sites can occur so we add gap sequences. Finally we append a stop codon region, restriction site preventing gapped error correcting region and hangs in each BabbleBrick form. For example:
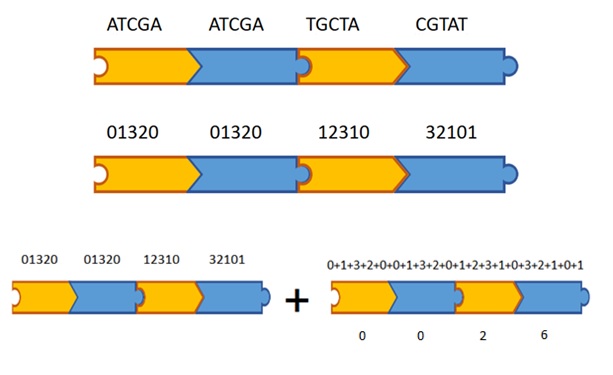
When we assemble our BabbleBricks together to create BabbleBlocks its vital we know what the sequence will be for both verification purposes, so that we can instruct the user exactly which BabbleBricks to use and so we can work out our checksum and address values. We start by appending our word coding BabbleBricks together:

We then look at the word coding regions spaced at regular and use them to calculate a checksum as described in the checksum section below. Finally, we append an address BabbleBlock which acts like a line number telling the decoding program where this BabbleBlock lies in the overall archive.
In order to decode a BabbleBlock we first look at our checksum and use it to verify whether or not error correction needs to be done - if some mistakes are flagged we use our error correcting apparatus, as described below, and return their results (what our sequence was before the change) back to the decoding program. The error correcting program will look at each word coding region, convert it back to it numerical values and use it as an index to look up the information value of that BabbleBrick in the lexicon. Having decoded all the BabbleBlocks in a batch these will then be sorted in order using the address found at the end of each sequence before the decoded information is returned to the user.


