Difference between revisions of "Team:Edinburgh UG/Software"
F1yingFish (Talk | contribs) |
F1yingFish (Talk | contribs) |
||
| Line 234: | Line 234: | ||
<p> </p> | <p> </p> | ||
<centre style="font-size:160%;">When the user starts up the BabblED software they are presented with the following screen and options.</centre> | <centre style="font-size:160%;">When the user starts up the BabblED software they are presented with the following screen and options.</centre> | ||
| + | <p> </p> | ||
<img src="https://static.igem.org/mediawiki/2016/a/a8/EdiGEMug16softhome.png"> | <img src="https://static.igem.org/mediawiki/2016/a/a8/EdiGEMug16softhome.png"> | ||
| + | <p> </p> | ||
<centre style="font-size:160%;">Lets assume that this is the users first time with the BabblED software. A natural first move would be to select the ReadMe option from the menu. This will display a piece of text with brief explanations of the informatics concepts behind BabblED.</centre> | <centre style="font-size:160%;">Lets assume that this is the users first time with the BabblED software. A natural first move would be to select the ReadMe option from the menu. This will display a piece of text with brief explanations of the informatics concepts behind BabblED.</centre> | ||
| + | <p> </p> | ||
<img src="https://static.igem.org/mediawiki/2016/d/d8/Edigemug16softreadme.png"> | <img src="https://static.igem.org/mediawiki/2016/d/d8/Edigemug16softreadme.png"> | ||
| + | <p> </p> | ||
<centre style="font-size:160%;">After reading through the user decides they would like to look at a lexicon. Now there are two options the user can use the ogdan's basic english (ogdan's basic english being a collection of the most expressive words in english) lexicon that comes with the BabblED distributable.</centre> | <centre style="font-size:160%;">After reading through the user decides they would like to look at a lexicon. Now there are two options the user can use the ogdan's basic english (ogdan's basic english being a collection of the most expressive words in english) lexicon that comes with the BabblED distributable.</centre> | ||
| + | <p> </p> | ||
<img src="https://static.igem.org/mediawiki/2016/a/a3/EdiGEMug16softlex.png"> | <img src="https://static.igem.org/mediawiki/2016/a/a3/EdiGEMug16softlex.png"> | ||
| + | <p> </p> | ||
<centre style="font-size:160%;">Alternatively they can create their own lexicon. This simply requires having each individual piece of information they wish to encode on a separate line in a text file ready to be loaded into the program.</centre> | <centre style="font-size:160%;">Alternatively they can create their own lexicon. This simply requires having each individual piece of information they wish to encode on a separate line in a text file ready to be loaded into the program.</centre> | ||
| + | <p> </p> | ||
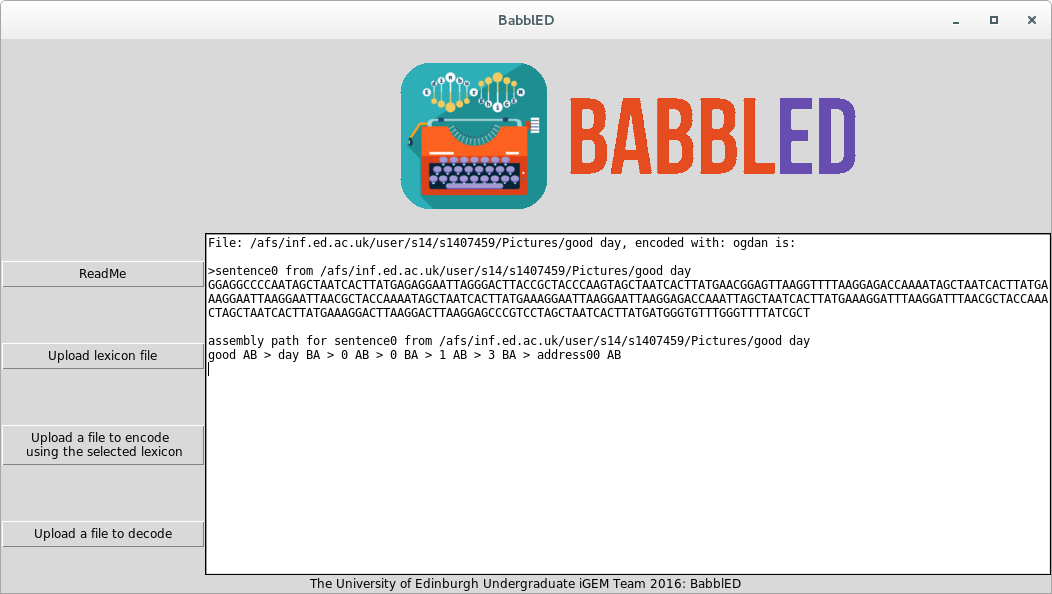
<centre style="font-size:160%;">After encoding a lexicon the next important functionality is to encode some piece of data. For this example we'll use some words from ogdans basic english for example good day. The user simply enters their information into a text file, like so:</centre> | <centre style="font-size:160%;">After encoding a lexicon the next important functionality is to encode some piece of data. For this example we'll use some words from ogdans basic english for example good day. The user simply enters their information into a text file, like so:</centre> | ||
| + | <p> </p> | ||
<img src="https://static.igem.org/mediawiki/2016/e/e0/Edigem16ugsoftgoodday.png"> | <img src="https://static.igem.org/mediawiki/2016/e/e0/Edigem16ugsoftgoodday.png"> | ||
| + | <p> </p> | ||
<centre style="font-size:160%;">This is then loaded into the program giving the sequence of the resulting BabbleBlock and the BabbleBricks required to encode it:</centre> | <centre style="font-size:160%;">This is then loaded into the program giving the sequence of the resulting BabbleBlock and the BabbleBricks required to encode it:</centre> | ||
| + | <p> </p> | ||
<img src="https://static.igem.org/mediawiki/2016/0/0f/Edigem16ugsoftencode.png"> | <img src="https://static.igem.org/mediawiki/2016/0/0f/Edigem16ugsoftencode.png"> | ||
| + | <p> </p> | ||
<centre style="font-size:160%;">Some time later we now need to retrieve this information. After getting the BabbleBlock from sequencing we load it into the program.</centre> | <centre style="font-size:160%;">Some time later we now need to retrieve this information. After getting the BabbleBlock from sequencing we load it into the program.</centre> | ||
| + | <p> </p> | ||
<img src="https://static.igem.org/mediawiki/2016/e/ed/Edigem16ugsoftseq.png"> | <img src="https://static.igem.org/mediawiki/2016/e/ed/Edigem16ugsoftseq.png"> | ||
| + | <p> </p> | ||
<centre style="font-size:160%;">Recieving back the encoded information with any necessary error correction already having been performed.</centre> | <centre style="font-size:160%;">Recieving back the encoded information with any necessary error correction already having been performed.</centre> | ||
| + | <p> </p> | ||
<img src="https://static.igem.org/mediawiki/2016/9/90/Edigem16ugsoftdecode.png"> | <img src="https://static.igem.org/mediawiki/2016/9/90/Edigem16ugsoftdecode.png"> | ||
| + | <p> </p> | ||
</div> | </div> | ||
<div class="col-sm-2"></div> | <div class="col-sm-2"></div> | ||
Revision as of 20:21, 19 October 2016